Cómo reconstruir las imágenes en tu cabeza por medio de tu actividad cerebral y Stable Diffusion
Se publicó hace unas semanas un paper académico muy curioso, y he hablado mucho de él con compañeros y amigos, pero quería dedicarle una entrada, más que nada para dejaros la referencia y que vosotros pudierais aportar vuestras opiniones e ideas al respecto, ya que el trabajo abre una línea de investigación que podría llevarnos a lo que hemos visto en muchas películas de ciencia ficción, o en los cómics, donde alguien sería capaz de ver las imágenes de los recuerdos de otra persona por medio de una Inteligencia Artificial que los recree en tiempo real.

Figura 1: Cómo reconstruir las imágenes en tu cabeza
por medio de tu actividad cerebral y Stable Diffusion
El artículo académico, titulado «High-resolution image reconstruction with latent diffusion models from human brain activity» explica en detalle cómo han hecho el estudio, así que podéis ir a ver los detalles más concretos en él, pero la idea de base me encanta, por ser un ejemplo de cómo aprovechar un avance para aplicarlo a algo que parece una locura.

Figura 2: «High-resolution image reconstruction with
Hoy en día, con los sistemas de Generative-AI podemos crear imágenes basadas en los inputs que les demos. Es sencillo irse a Dall-e y decirle un prompt para que nos genere una imagen. Tal vez no sea exactamente la que teníamos en mente, pero cuanto más afinemos el prompt, y más detalles le demos, podemos hacer que nos de resultados más ajustados a lo que estamos pensando. Eso sí, sin dejar que Dall-e nos lea la mente. Nos la leemos nosotros, la traducimos a lenguaje escrito, y compartimos con el modelo de Generative-AI en qué estamos pensando.

Figura 3: «Dibuja un caballo durmiendo en un charco de agua roja» en Dall-e
Si entrenamos uno de estos modelos, como en el caso del servicio de Stable Diffusion en MyPublicInbox, con nuestras propias imágenes, podemos pedirle que nos recree a nosotros. Imaginaos que cerramos los ojos, y pensamos en nosotros mismos bailando, y le pedimos a Stable Diffusion que nos cree tal y como estamos viéndonos en nuestra mente. Él lo hará.

Al final, lo que estamos haciendo es conectar una imagen que sólo vemos nosotros en nuestra mente con una salida construida por Stable Diffusion, usando para ello la interpretación que nosotros hacemos de esa imagen, y llevándola a un prompt concreto. Y así tenemos una imagen de lo que estamos pensando. ¿Es exactamente lo mismo? Depende de lo específicos que seamos a la hora de usar nuestro lenguaje para generar un prompt con lo que estamos pensando, y lo afinado que dejamos el modelo.
Modelos de Diffusion
Hay que tener en cuenta que estos modelos, como Stable Diffusion, se basan en hacer una difusión de los datos de entrada del dataset, por ejemplo los píxeles y colores de una imagen, para generar una representación difusa llamada «Espacio Latente» que posteriormente va a ser refinada mediante un algoritmo de eliminación del ruido para construir una nueva imagen basándose en los espacios latentes que consiga el objetivo demandado en algoritmo.

Figura 5: Proceso de difusión de imágenes.
Este proceso de «añadir ruido», lleva todos los datos del Dataset original, a imágenes latentes que no se parecen al original, pero que guardan una base informativa dependiente del dato original, por lo que van a ser buenas imágenes sobre las que construir la salida buscada por el prompt. En el artículo de «Cómo funciona Stable Diffusion – y Dalle-2 o Midjourney -: Open Source Generative-IA que crea imágenes artísticas«, se explica este proceso en detalle.

Así, cuando se le da un prompt de entrada, para generar una imagen, lo que hace el algoritmo es buscar espacios latentes asociados a esa cadena de datos de entrada sobre los que comenzar a iterar para cumplir el objetivo, eliminando el ruido y dirigiendo la construcción de la imagen. La magia es que cuando se hace el proceso de «denoising» mediante una o eliminación de ruido, usando Redes Neuronales Convolucionales (CNNs), en concreto, la red conocida como U-Net, se hace de manera dirigida.

Figura 7: Arquitectura U-Net
Gracias a que se produce un proceso de condicionamiento que permite construir totalmente nuevas imágenes, basadas en imágenes previamente convertidas en espacios latentes y mezcladas, al final se logra generar una imagen de calidad que responde al prompt concreto de entrada que se ha solicitado. El paper de «High-Resolution Image Synthesis with Latent Diffusion Models» de año 2022 explica cómo funciona este proceso para sacar imágenes de gran calidad.

Podríamos resumir entonces que el proceso se basa en mezclar imágenes en espacios latentes que cumplen parte del prompt solicitado, para luego, con un proceso de denoising dirigido usando una CNN, conseguir que la imagen resultante pase el filtro discriminador asociado al prompt de entrada completo. Y funciona.
Cerebro como Prompt de entrada
Como hemos visto, todo el proceso anterior se basa en tener un Dataset de imágenes de origen asociado a prompts que luego se convierten en espacios latentes asociados a prompts, que luego, para obtener una nueva imagen asociada a un nuevo prompt, se mezclan en espacios latentes y se hace un denoising para pasar el filtro discriminador del objetivo a conseguir.

Figura 9: Se utiliza un modelo LDM para codificar
y decodificar las imágenes asociadas a fMRI
Pues bien, lo que propone el paper de «High-resolution image reconstruction with latent diffusion models from human brain activity» es utilizar la actividad cerebral de una persona en forma de imagen de resonancia magnética funcional, llamadas (fMRI) para asociar a ellas, los estados latentes de las imágenes, las cadenas de texto que definen las imágenes, y la suma de las mismas, con la imagen fMRI, es decir la actividad cuando el cerebro ve la imagen latente y oye la cadena de texto.
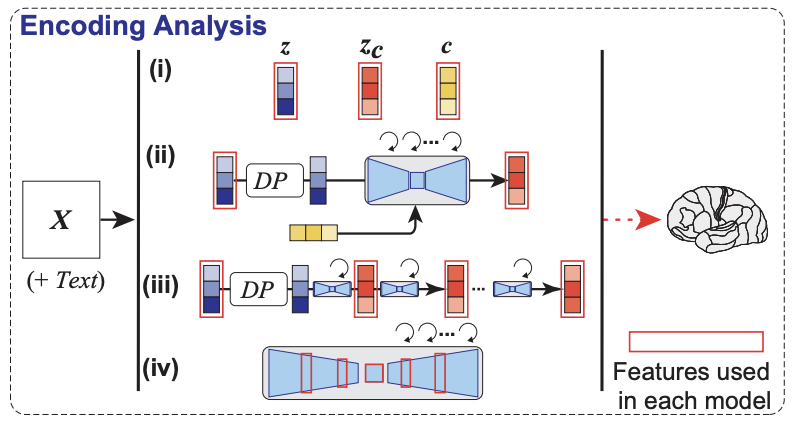
Figura 10: Se asocian las imágnes fMRI asociadas a visualizar z (imagen latente de la imagen presentada), c (texto descriptivo de la imagen presentada), y zc (imagen latente de la imagen presentada más texto descriptivo).
A partir de ese momento, lo que hay es un Dataset de estados latentes asociados a imágenes fMRI que se utilizará de base para generar los datos de entrada. Así, después se le enseñará una imagen a la persona, y se capturará su fMRI, que dispara el proceso de inicio seleccionando las imágenes latentes correctas para construir la base que disparará el proceso de «denoising«.

Figura 11: Decodificación a partir de fMRI (como prompt de entrada)
Como se puede ver, en este caso la imagen latente está guardada con su prompt en forma de texto, así que en la decodificación final, después de seleccionar las imágenes latentes, se usa el prompt asociado a esas imágenes para refinar el proceso. El resultado es que a partir de una imagen fMRI, teniendo los datos asociados, se puede «ver» más o menos, la imagen en lo que está pensando.

Figura 12: Ejemplos de imágenes presentadas y resultados obtenidos.
Por supuesto, el resultado aún es muy preliminar, y dependiendo de cada una de las personas, las imágenes fMRI pueden modificarse, así que el entrenamiento de datos puede funcionar mejor o peor, pero los resultados son muy prometedores. Aquí con varios sujetos totalmente diferentes.

Figura 13: Con varias personas distintas, resultados similares
Esto parece un poco de ciencia ficción, pero al final se trata de decirle a un modelo de Stable Diffusion qué es lo que debe dibujar, pero en lugar de utilizar como prompt de entrada nuestras palabras, usamos nuestras imágenes de una resonancia magnética cuando pensamos en esa imagen.
 |
| Figura 14: Libro de Machine Learning aplicado a Ciberseguridad de Carmen Torrano, Fran Ramírez, Paloma Recuero, José Torres y Santiago Hernández. |
Y mola mucho. Además, desde el punto de vista policial podría abrir nuevas vías de interrogar a los sospechosos en el futuro, y se abren también retos de ciberseguridad y privacidad. ¿Seremos capaces de proteger nuestros pensamientos de análisis futuros? ¿Podrá remotamente capturarse nuestra actividad cerebral como en los ataques Tempest y saberse qué estamos pensado? Apasionante el mundo que viene.
¡Saludos Malignos!
Autor: Chema Alonso (Contactar con Chema Alonso)

Powered by WPeMatico