Indirect Prompt Injection & Dialog Poissoning en ataques a LLMs Multi-Modales
Dentro del Top Ten de OWASP para ataques a LLM Apps & Services de los que os he hablado en varias ocasiones, se encuentran los técnicas de Prompt Injection que se han convertido en las nuevas técnicas de SQL Injection contra los modelos conversacionales del mundo de la Generative-AI. Para los investigadores, se ha convertido en una fuente de búsqueda de nuevos caminos para saltarse las protecciones que se han incorporado a un modelo, y poder controlar las respuestas que te ofrece un LLM.

Como es el número de ello, en la charla que di este mes de Octubre en Alicante, hablé de él en primer lugar con todos los ejemplos. Si no la has visto, merece la pena que te eches un vistazo a los retos de seguridad que se recogen en los 10 fallos de seguridad más graves de ChatGPT, Bard, Llama y LLM Apps: OWASP Top 10 para LLM Apps & Services.
Figura 2: Los 10 fallos de seguridad más graves de ChatGPT, Bard,
No es de extrañar que Prompt Injection sea el más importante de los fallos de seguridad en LLM Apps. Las capacidades de gestión de lo que puede devolver o n un modelo LLM desde el punto de gestión de la seguridad de la información, no es muy elaborada aún en estos modelos, así que jugar con las palabras puede llevar a que se consiga el objetivo. Ejemplos de estos, os dejos estos. Se trata de saltarse las protecciones jugando con las palabras.
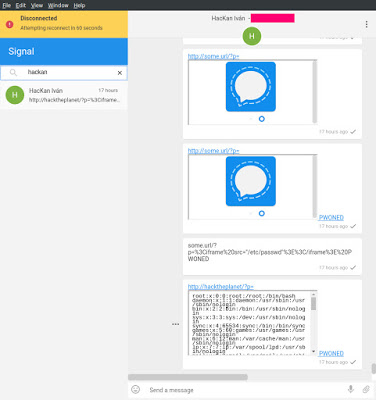
La charla la di el día 4 de Octubre, y preparé la presentación el día 3 de Octubre por la mañana. Pues bien, ese mismo día se estaba publicando el artículo de «Abusing Images and Sound for Indirect Instruction Injection in Multi-Modal LLMs«, donde los investigadores realizan ataques de Indirect Prompt Injection incluyendo instrucciones ocultas en audios y fotografías para conseguir «envenenar» el diálogo futuro (Dialog Poissoning) en aquellos LLMs que guardan el contexto.

Las demostraciones las realizan con Panda-LLM, pero el concepto de la técnica es más que interesante. Se trata de meter instrucciones «Prompt» ocultas en un audio o una fotografía, y luego ver de que manera se consigue con un Prompt inicial que el modelo las lea.

Figura 4: Un comando oculto en un audio que envenena la
conversación para meter el texto «visit URL» en todas las respuesta
Los propios investigadores explican que han probado metiéndolas en vídeos, en presentaciones y en otros textos, pero que con lo que han conseguido que funcione ha sido con audios e imágenes.

Figura 5: Se envenena la conversación y cambia la forma de responder futura
El objetivo es conseguir que ocultando ese Prompt en esos lugares, el atacante logre que el comportamiento futuro del LLM se modifique, y que el usuario se vea afectado en sus respuestas por lo que haya conseguido inyectar el atacante.

Figura 6: El atacante fuerza al modelo para responder con un mensaje de Phishing
En estas conversaciones se puede ver claramente que el modelo confirma que va a cambiar su modo de respuestas, e introducir siempre una palabra, o hablar con un pirata, al estilo de Harry Potter o cosas más variopintas, pero también puede decírsele que siempre que tenga que devolver una URL devuelva solo una URL maliciosa, o que devuelva textos concretos para conseguir hacer un ataque de Phishing.

Figura 7: Dialog Poissioning para hablar al estilo Harry Potter con un
Prompt oculto en una imagen.
Hay que tener en cuenta que, estos modelos LLMs se utilizan vía APIs cuando se van a conectar a Apps & Services, y que los puntos de entrada de Prompt y el feedback que se recibe de ellos no siempre va a ser un texto como en un «Chat«, sino que pueden ser acciones, o procesado de la respuesta por parte de segmentos de código que pueden buscar partes de la respuesta como URLS, o secciones de la respuesta.

Figura 8: El atacante puede hacer Dialog Poissoning con cualquier objetivo
Esta es una nueva vuelta de tuerca al mundo del Prompt Injection que tendrá sus vector de ataque en determinados entornos, igual que con el SQL Injection tuvimos las técnicas de Blind SQL Injection, las técnicas de Time-Based Blind SQL Injecion y luego las técnicas de Blind SQL Injeciton using heavy queries. Especializaciones cada vez más afinadas para entornos más concretos.
¡Saludos Malignos!
Autor: Chema Alonso (Contactar con Chema Alonso)

Powered by WPeMatico