
Cazando con Inteligencia Artificial: Detección de dominios maliciosos (III)
Esta entrada y la serie en su conjunto ha sido elaborada conjuntamente con Ana Isabel Prieto, Sergio Villanueva y Luis Búrdalo.
En anteriores artículos de esta serie (ver parte I y parte II) se describió la problemática de la detección de dominios maliciosos y se proponía una forma de abordar dicho problema combinando diversas técnicas y algoritmos estadísticos y de Machine Learning. También se describía el conjunto de variables a partir de las cuales se caracterizarán dichos dominios para su posterior análisis por parte de los mencionados algoritmos de Machine Learning. En esta última entrega se describen los experimentos llevados a cabo y los resultados obtenidos.
Las pruebas realizadas se han llevado a cabo contra un total de 78.661 dominios extraídos del tráfico, a priori legítimo, de una organización, a partir de los cuales se han calculado 45 características léxicas pertenecientes a las categorías descritas anteriormente.
Parámetros
Cada uno de los algoritmos comentados anteriormente se ha ajustado a través de un único parámetro:
- El algoritmo Isolation Forest se ha ajustado mediante el valor del parámetro “contamination”. Este parámetro indica la proporción máxima de valores atípicos en el conjunto de datos; es decir, cuanto mayor es el valor de este parámetro, más datos se van a detectar como atípicos.
- En el caso del algoritmo SVM One-class, el parámetro de ajuste es “nu”, cuyo valor puede estar comprendido entre 0 y 1. Este parámetro indica un límite superior de la fracción de errores de entrenamiento (máxima proporción de valores atípicos que se espera en los datos) y un límite inferior de la fracción de vectores de soporte (mínima proporción de puntos en el límite de decisión). De esta manera, este parámetro permite ajustar el equilibrio entre el sobreajuste y la generalización del modelo.
En el dataset se han introducido, junto con todos los demás datos, los siguientes 5 dominios maliciosos relacionados con campañas de phishing y descarga de malware. Éstos son los ejemplos utilizados en este artículo para determinar la eficiencia de los algoritmos de ML en la detección de dominios maliciosos.
- ukraine-solidarity[.]com
- istgmxdejdnxuyla[.]ru
- correos-servico[.]com
- hayatevesigar-10gbnetkazan[.]com
- 57486662l4[.]xyz
Las pruebas se han realizado con los siguientes valores para los parámetros:
Tabla 1: Valores de los parámetros “Contamination” y “nu”, utilizados para la prueba.
| Modelo | Parámetro | Valor |
| Isolation Forest | Contamination | 0.002 |
| One Class SVM | nu | 0.002 |
Resultados y detecciones
Con los parámetros mencionados, los más de 78.000 dominios estudiados se ven reducidos a 359 por, al menos, alguno de los dos modelos no supervisados, sin aplicar ningún tipo de ponderación sobre ellos. De los 5 dominios maliciosos escogidos para evaluar la fiabilidad, se detectan 3 de ellos, siendo:
| Dominio | Isolation Forest | One Class SVM |
| istgmxdejdnxuyla[.]ru | — | X |
| hayatevesigar-10gbnetkazan[.]com | — | X |
| 57486662l4[.]xyz | X | X |
Como se ha comentado anteriormente, con el PCA se extraen las componentes principales necesarias para explicar el 95% de la varianza. En este caso, se extraen un total de 15 componentes principales, las cuales van a ser las características que los algoritmos de ML van a utilizar para detectar los dominios anómalos.
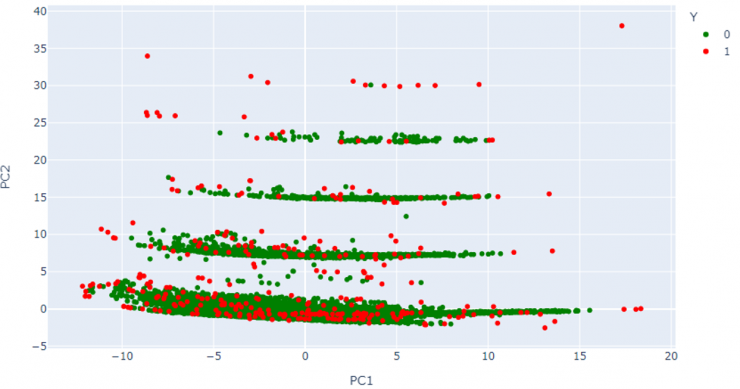
En la Figura 5 se muestra la representación en 2D de las dos primeras componentes (PC1, PC2), donde se pueden observar diferentes agrupaciones de datos según sus características léxicas. En ella, se han representado en color verde los dominios que sean considerados legítimos y en color rojo, aquellos que se han marcado como anómalos. Que un dominio se aleje de un grupo indica que contiene características diferentes a las de ese grupo. De esta manera, cuanto más se aleje un dominio de los demás dominios del dataset, más probable es que sea detectado como anómalo.
Cabe destacar que, aunque algunos de los dominios clasificados como anómalos parece que no se alejan del resto en esta representación bidimensional, hay otras 13 dimensiones adicionales que los algoritmos tienen en cuenta, por lo tanto, en alguna de ellas estos dominios deben separarse significativamente del resto.
Para reducir el número de dominios anómalos a revisar, se utiliza la lista de los 10000 dominios más comunes de Alexa. De los 359 dominios anómalos iniciales, 21 pertenecen a esta lista, quedando un total de 338 dominios anómalos.
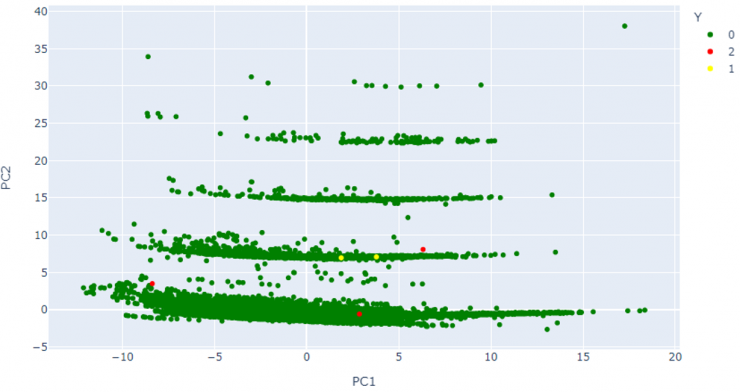
En la Figura 6, se muestra esta misma representación, pero destacando con distintos colores los dominios maliciosos añadidos a posteriori en esta base de datos, tanto los detectados como anómalos por los modelos, como los no detectados.
Conclusiones
En esta serie de artículos se muestra un ejemplo de cómo emplear algoritmos de ML para detectar anomalías, reduciendo así, de manera drástica, la cantidad de información a ser revisada por los analistas y contribuyendo además a la automatización del proceso de caza y detección.
Los algoritmos han reducido en gran medida el pool de datos (338/78.000 = 0,0043; es decir, que se ha reducido el conjunto de dominios a revisar en, aproximadamente, un 99,6%). Los algoritmos de ML empleados en este ejemplo han sido capaces de identificar 3 de los 5 dominios maliciosos introducidos en la base de datos de prueba.
Los dominios maliciosos no detectados como anómalos fueron ukraine-solidarity[.]com y correos-servico[.]com. Si se analizan dichos dominios se puede apreciar claramente que la causa probable de ello es que las características léxicas de ambos son muy similares a las de los dominios comúnmente legítimos.
Aunque no se han descrito en este artículo por no extenderse demasiado, se han llevado a cabo múltiples pruebas con diferentes valores de los parámetros “Contamination” y “nu” de los algoritmos. Los resultados de las mismas mostraron que ambos algoritmos son muy sensibles a dichos parámetros. A fin de reducir de manera significativa la cantidad de información inicial a ser revisada manualmente por los analistas sin por ello perder precisión en la clasificación, interesa emplear unos valores bajos para estos parámetros. Sin embargo, esto puede llegar a suponer una cantidad de falsos negativos, no llegando a detectar correctamente una gran cantidad de dominios maliciosos. El correcto ajuste de estos parámetros ha de llevarse a cabo de manera cuidadosa.
Una posible forma de lidiar con este problema puede ser la correlación de diferentes métodos de detección, tanto tradicionales basados en reglas como los que utilizan algoritmos de IA o ML.
La entrada Cazando con Inteligencia Artificial: Detección de dominios maliciosos (III) aparece primero en Security Art Work.
Powered by WPeMatico


