
Vitaminando Crowdstrike con Apache NiFi a coste 0

Tras una pequeña desconexión «paternal» , volvemos al lio, con algo en lo que he estado trabajando estos últimos meses. Una herramienta que me tiene totalmente enamorado, y con la que los procesos de cyberseguridad, su automatización y el tratamiento de los datos, tienen un antes y un después con ella.
De forma resumida, es una herramienta , con la que podríamos hacer todas las funciones de un XSOAR , más todas las funciones de un ETL , todo ello, OpenSource, a coste 0 ( En este punto se me saltan hasta las lagrimas ) a nivel licenciamiento ojo no HW. Aunque también, y como toda herramienta tienen carencias, aunque nos centraremos en su potencial.
Podríamos hacer todas las funciones de un XSOAR , más todas las funciones de un ETL , todo ello, OpenSource, a coste 0
A lo largo del post, me centraré en una pequeña parte de un automatismo en el que he estado trabajando, pero con el que podréis ver el potencial de la herramienta, sumado a Crowdstrike y su API, que puede ser actualmente una de las mejores de los fabricantes, ya no solo de EDR, si no a nivel global.
¿ Que es exactamente Apache NIFI ?
Apache NiFi es una plataforma OpenSource de logística de datos capaz de mover datos entre sistemas, teniendo la capacidad de tratar los mismos por el camino, por ejemplo. La verdadera belleza de NiFi radica en su simplicidad y facilidad para desarrollar flujos de datos que involucran de millones a miles de millones de eventos entre sistemas con una semántica de entrega garantizada ( Luego aterrizaremos la facilidad, que en algunos casos no es tan sencilla ). Apache NiFi, como dice , dimensionándose en cluster, nos da la capacidad de tratar millones de eventos sin problemas, proporcionando un control en tiempo real sobre los datos (o eventos) que facilita la gestión del movimiento de datos entre cualquier fuente y cualquier destino, aunque no será el caso de nuestro ejemplo ( Pero tener presente el tratamiento de eventos, hasta podríamos montarnos un SIEM ).
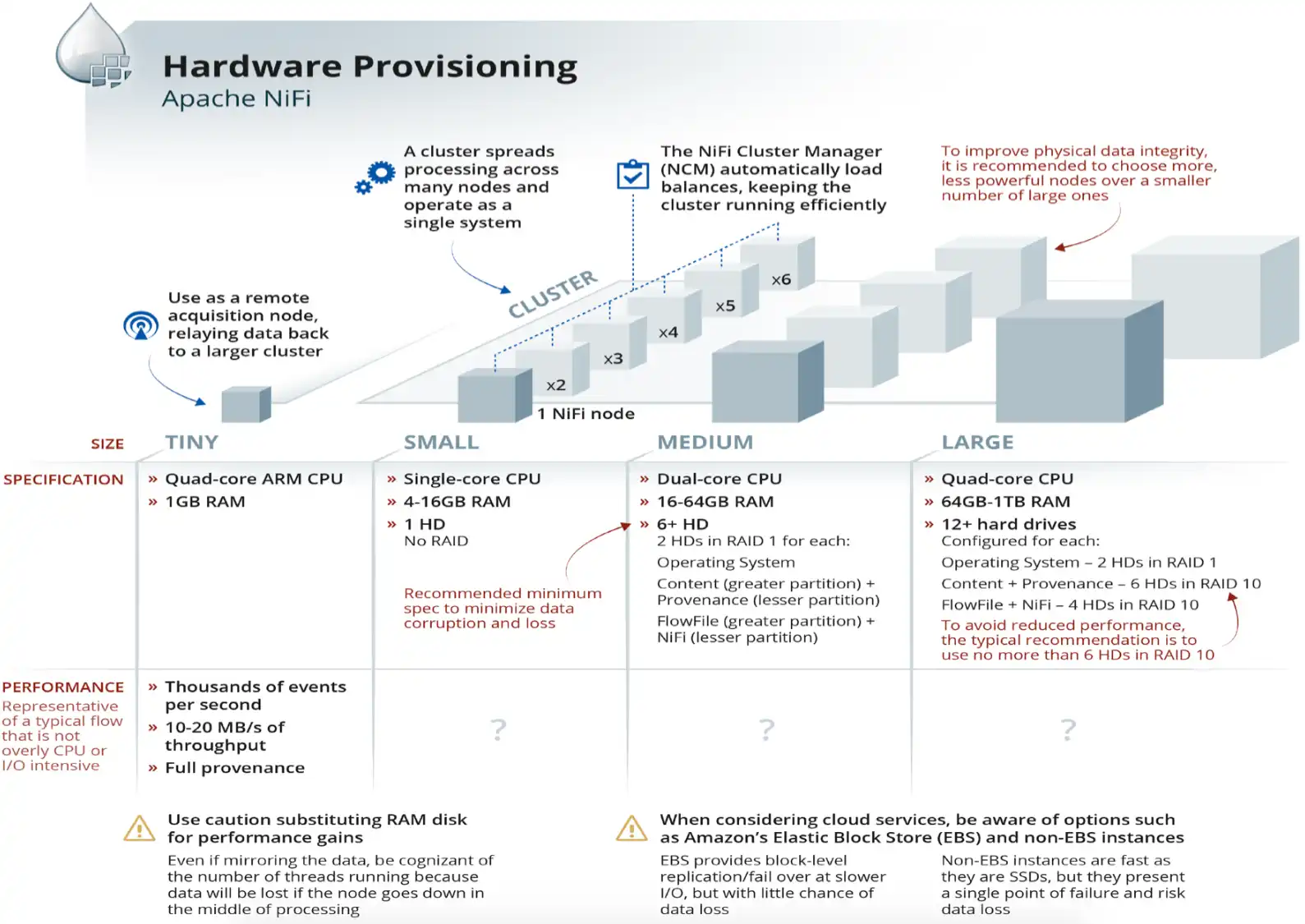
NiFi es independiente de la fuente de datos, por lo que admite fuentes y formatos dispares. Acepta flujos de datos TCP/UDP, puede leer datos de RDBMS, puede extraer datos de REST API ( nuestro ejemplo ), puede leer datos de archivos de registro al mismo tiempo que nos permitirá analizarlos, enriquecer y transformarlos en tiempo real. NiFi es un controlador de información híbrido y un procesador de eventos en tiempo real. Esta característica de NiFi lo hace super adecuado para la ciberseguridad, donde el ritmo de los datos, es constante y el tratamiento debe ser instantáneo, una joyita para nuestro SOC vamos.
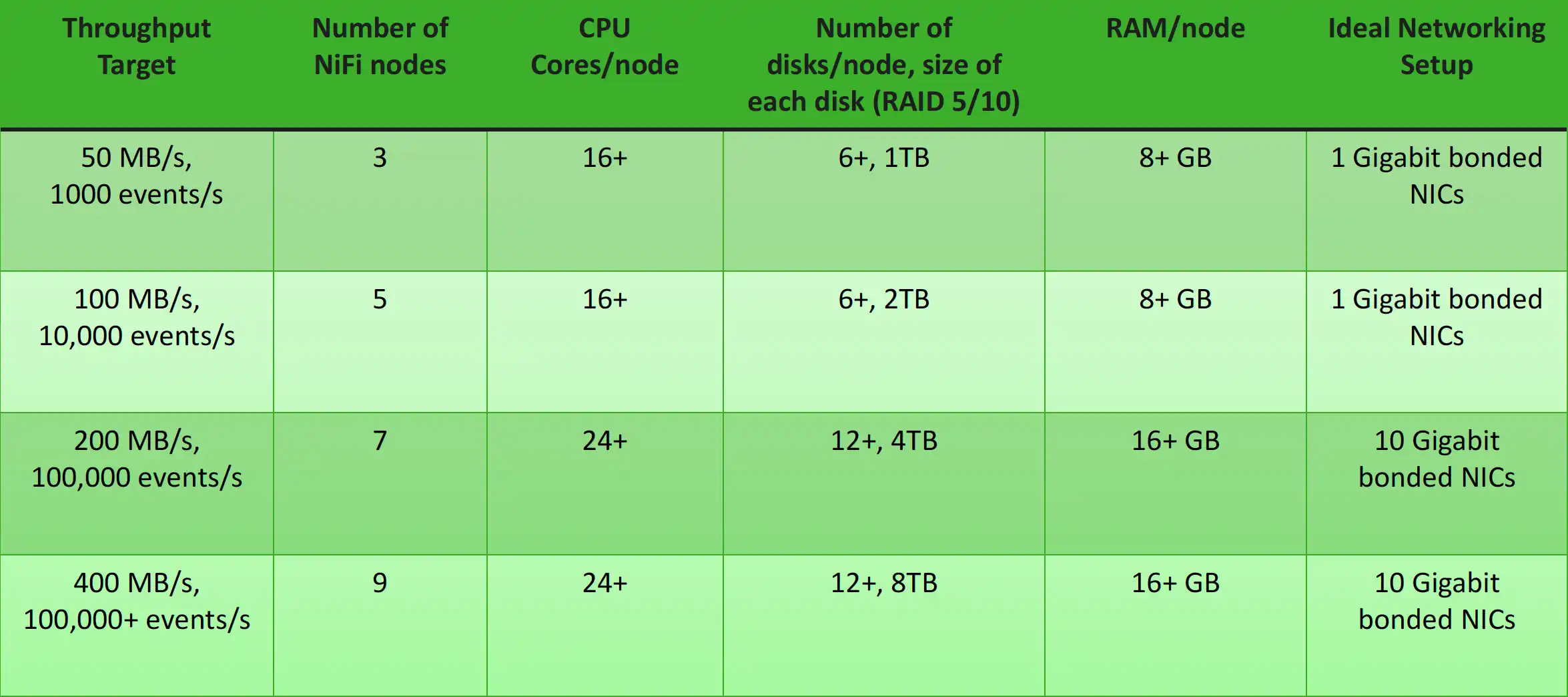
Os dejo una pequeña tabla en el que muestra el Througput del sistema en eventos y las sorprendentes cifras si dimensionamos correctamente el sistema. Si montamos un cluster en Kubernetes las posibilidades se incrementan notablemente, aunque la adhesión de nuevos nodos al cluster es muy sencilla con Zookeeper. ( Si tenéis alguna duda técnica , escribirme sin problemas ).
Componentes de NiFi y su funcionamiento
NiFi tiene 3 componentes principales, archivo de flujo, procesadores y conectores:
No os alarméis, os dejo el canal de Steven Koon, mi principal gurú a la hora de aprender NiFi de forma autodidacta. ( Hasta un zote como yo, puede montar algo medio curioso, viendo solo los videos de Steve ).
- Flowfiles: Los Flowfiles en NiFi son los contenedores de datos. Los archivos de flujo son las unidades de datos básicas en NiFi. Cada Flowfile debe contener al menos un evento. Los Flowfiles tiene dos partes importantes: los atributos y la carga útil o datos. Los archivos de flujo generalmente comienzan con un conjunto predeterminado de atributos que luego se agregan mediante operaciones adicionales. Se puede hacer referencia a los atributos a través del lenguaje de expresión NiFi. La carga útil suele ser la información en sí misma y también puede ser referenciada por procesadores específicos.
- Procesadores: Estos hacen el trabajo real en NiFi. Los procesadores son segmentos de código autónomos que encapsulan la lógica real del usuario. Un procesador en NiFi acepta archivos de flujo de entrada y proporciona un conjunto de archivos de flujo como salida después de aplicar la lógica encapsulada en cada evento. NiFi tiene actualmente más de 350 procesadores que sirven para diferentes propósitos. El procesador de archivos de flujo «InvokeHTTP«, sobre el que luego trabajaremos más, es un procesador de archivos de flujo de ejemplo que ayuda a publicar eventos usando HTTP POST o para obtener eventos de la API usando una llamada GET. ( Ya tenemos el germen de nuestro XSOAR ) , por ejemplo, este es parte del ejemplo que veremos , en el que trabajamos con la API de Crowdstrike.
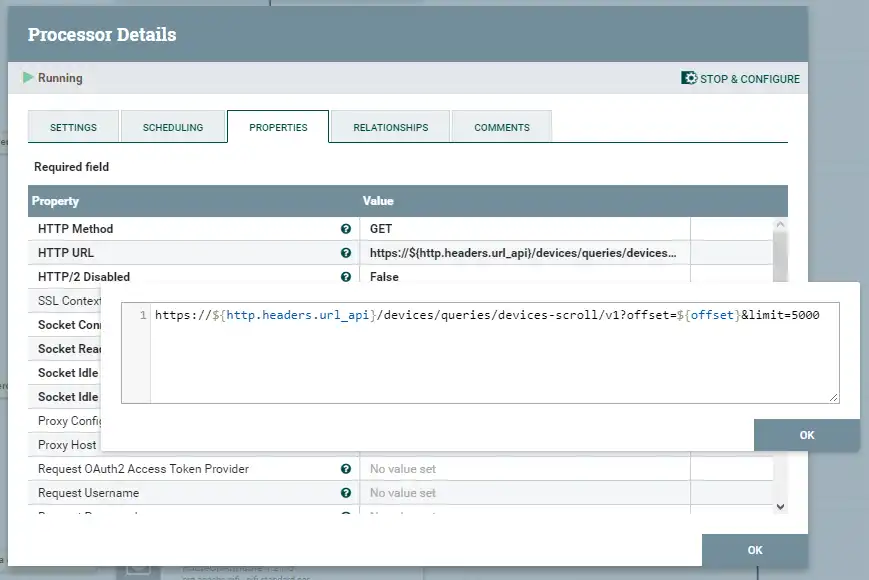
- Conectores: Estos detallan cómo deben «viajar» los archivos de flujo entre los procesadores. Las conexiones comunes son éxito/fracaso, un simple pero efectivo manejo de errores para los procesadores. Los archivos de flujo que se procesan sin fallos se envían a la cola de éxito, mientras que los que tienen problemas se envían a la cola de fallo, pudiendo volverse a tratar.
Todo en NiFi sucede en un flujo de datos. Un usuario puede diseñar el flujo de datos definiendo cómo el flujo de datos recibe, procesa y envía datos utilizando un conjunto de procesadores preconstruidos o escribiendo un procesador personalizado. Y esto es lo que veremos en el post, un flujo de datos de tratamiento y obtención de datos en NiFi sobre el API de Crowdstrike.
Con esto, y sin entrar en mucha profundidad en el funcionamiento, vamos a ver como poder potenciar la API de Crowdstrike, que como comento anteriormente, puede ser una de las mejores del mercado.
Generando Informes de Crowdstrike para nuestro SOC con NiFi
En el caso que os traigo, y sobre el que he estado trabajando estos últimos meses, cubre una función clara y principal, Automatizar la obtención de información, la generación de informes y el tratamiento de la misma.
Podríamos, desde crear un SIEM, meter las reglas que Crowdstrike nos detecte con los IoC directamente en los Firewalls, conectarla con Reyes o Lucia del CCN , mandarnos un mail cuando detecte un posible agente duplicado, agentes sin conexión …. Como comento, las opciones son infinitas, pero en este caso, supongamos que necesitamos generar los informes de manera automatizada , pero a demanda de nuestros clientes del SOC con Crowdstrike ( La metodología es la misma para otras tecnologías por ejemplo ), para lo que diseñaremos un listener webshocket en NiFi, sobre el que pasemos la información del cliente concreto, y el mismo nos devuelva una salida en JSON con la información tratada …. maravilloso verdad 😉
Veamos un ejemplo de la petición a nuestro listener a NiFi ( la ip 65.20.96.214 es un hosting ) y la obtención de información de nuestro Tenant.
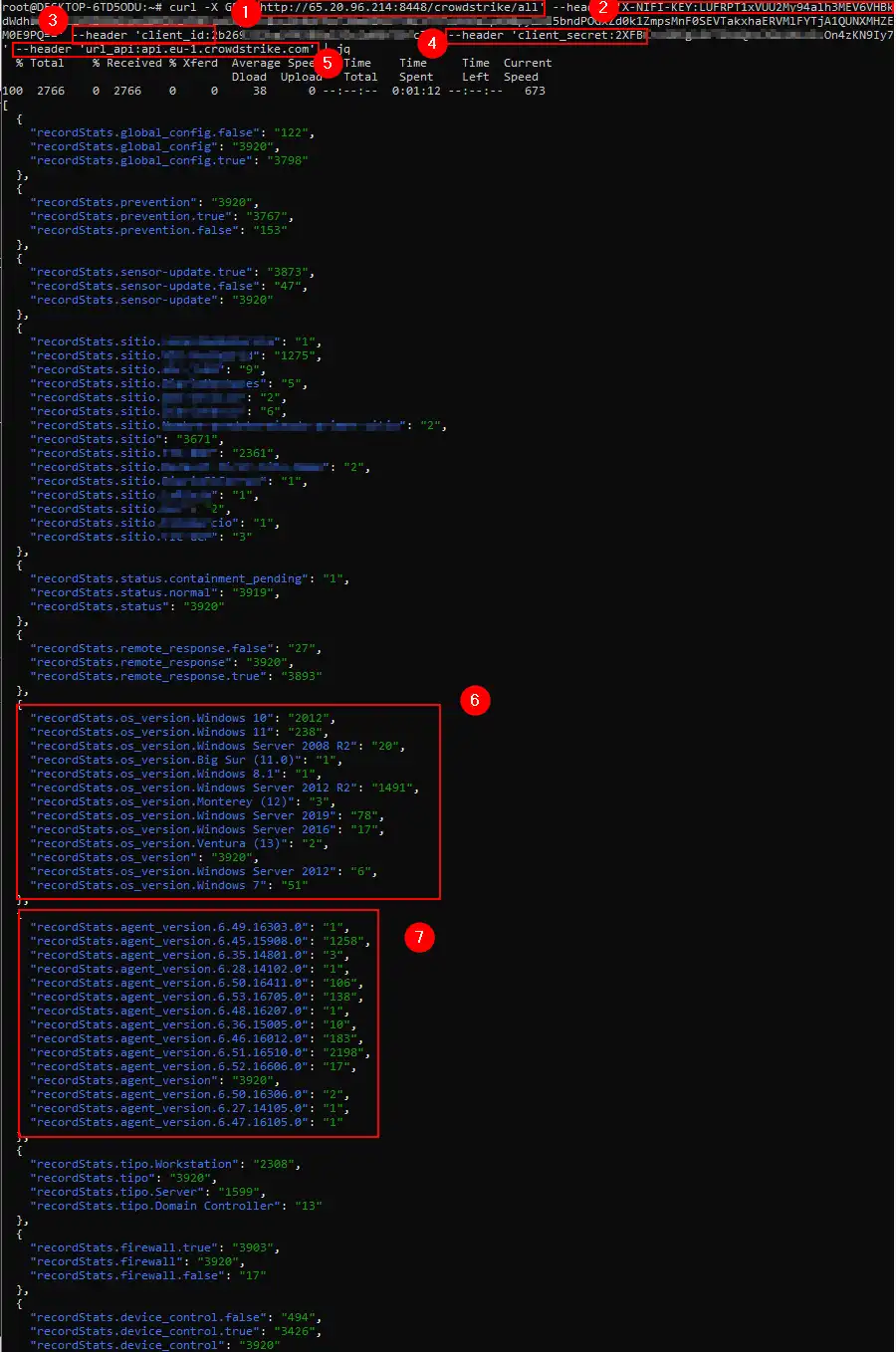
- Pido la petición a mi listener de NiFi ( 65.20.96.214 ), sobre el que publico el puerto 8448, y le pido una información concreta ( /crowdstrike/all ) . Desglosaremos esto mas adelante
- A modo Auth y de forma que no pueda solicitar cualquiera información, meto una cabecera de control ( no quería montar un ldap para hacer la prueba ) , por lo que tengo un control de dicho parámetro que básicamente , si esta bien pasa, si no nos devolverá un error 403 Forbidden.
- Como el sistema se basa en el tratamiento de información multicliente, paso los datos del mismo en el header ( 3 – 4 – 5 ). Toda la info que pasamos, NiFi lo tratara como atributos, sobre los que podremos trabajar más adelante.
- Como resultado, por ejemplo, podemos obtener de una forma sencilla , datos de nuestro parque de agentes instalados de Crowdstrike, nuestro parque de equipos, aplicaciones de políticas, estadísticas por sitios … etc.
Un ejemplo, que nos da de una forma sencilla las posibilidades que tendríamos, por ejemplo, a la hora de controlar los despliegues en la fase de provisión y la aplicación de políticas. Tratamiento de IoCs , generación de alertas, reports ….. Os muestro la punta del iceberg de opciones que tendríamos, ya que NiFi, tienen componentes nativos de tratamiento de kafka, bigdata, syslogs , conectores S3 AWS, dropbox ….. A mi me tiene enamorado.
Y para llegar a esto, es tan sencillo, como la creación lógica de «cajitas» de tratamiento de datos, os muestro mi ejemplo, y os lo compartiré más adelante:
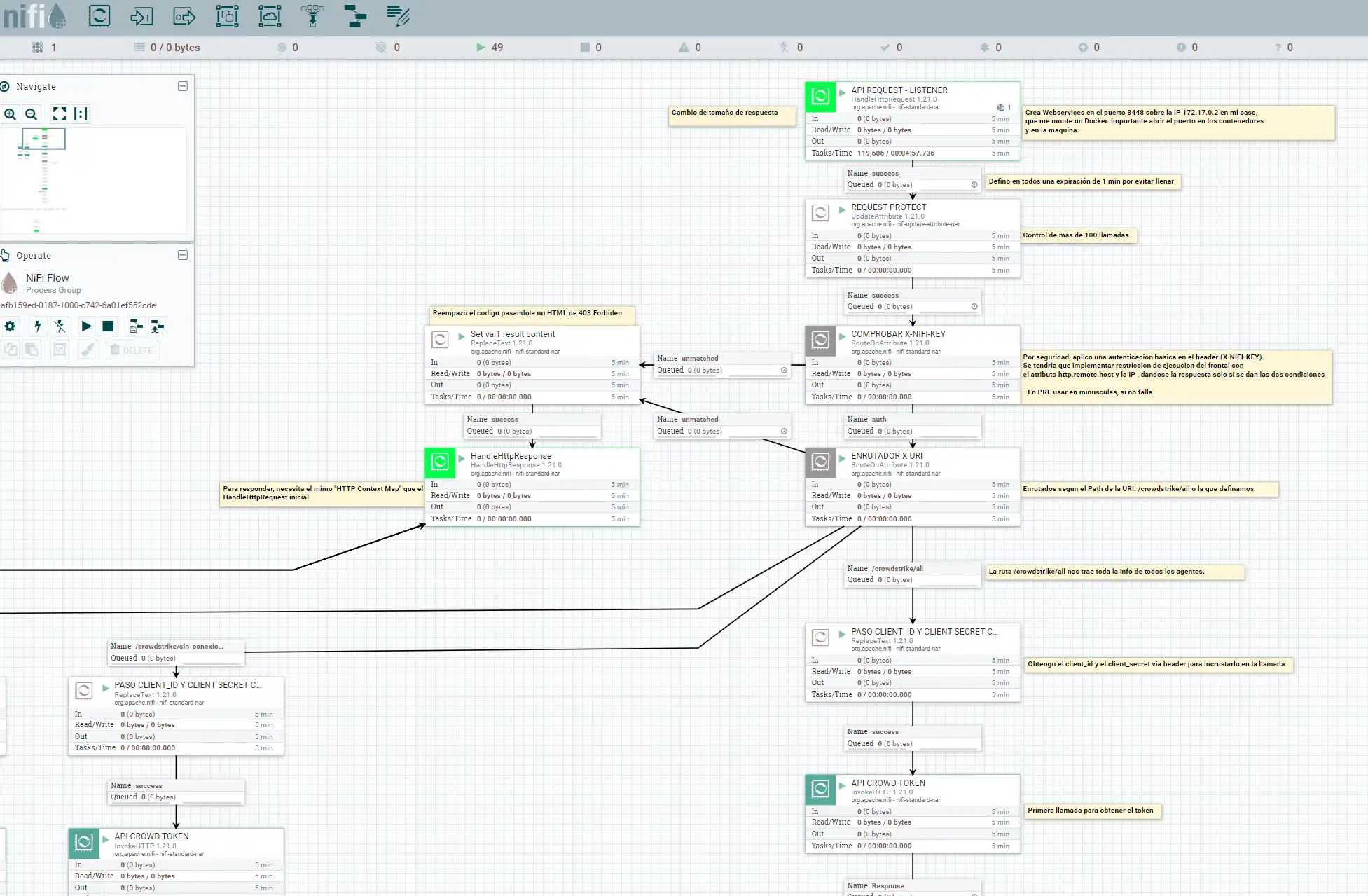
Os dejo el template sobre el que os contare con un pequeño ejemplo, como podemos vitaminar nuestro Crowdstrike con NiFi, obteniendo en lugar de con un SDK , datos del API que posteriormente podremos tratar, pintar o similar.
Os dejo la plantilla de la creación de un listener para Crowdstrike en NiFi:
NiFi genera un xml exportable sobre la misma. Como comenté, no entraré en profundidad en NiFi, si no en el propio ejemplo, para conocer la herramienta, os animo como os indicaba antes, a ver los videos de Steve.
Trabajando con Crowdstrike desde NiFi
Ahora, desgranemos poco a poco el ejemplo de la plantilla que os he subido:
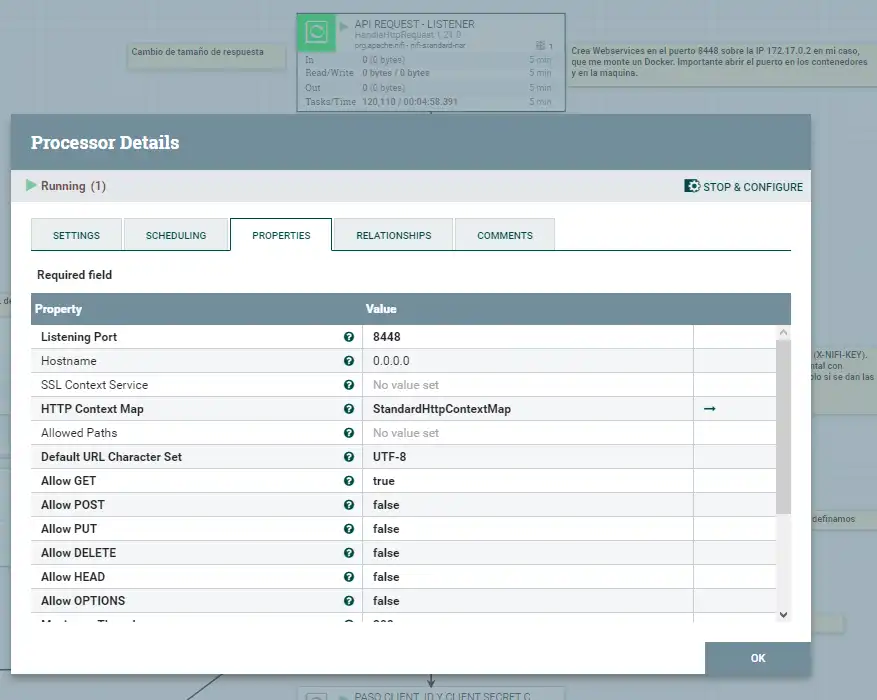
El punto de partida en nuestro caso, es la creación de un listener ( en el puerto 8448 en mi caso ), sobre el que nos contestará con la información que le pidamos. Como os comento en la plantilla, y tras varios casos, he montado NiFi, en standalone , cluster, en Docker, Kubernetes …. lo que hace variar la configuración de la IP del listener ( Por ejemplo, Docker nos genera unas subinterfaces 172.X.X.X o similares ) , Kubernetes nos valdría ponerlo en la localhost 0.0.0.0 , posiblemente debáis modificar en base a lo que tengáis instalado.
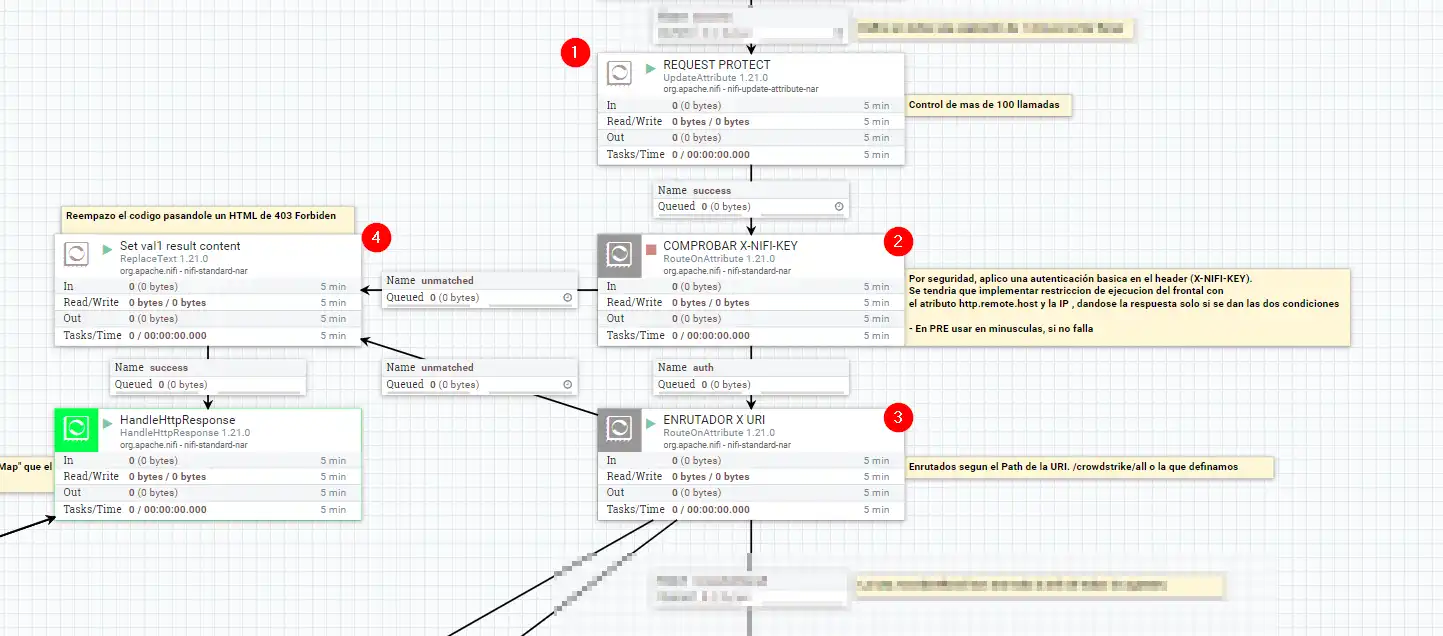
Si continuamos bajando , en ( 1 ) podría decirse que es una composición de control , en la que controlo que no se realicen más de 100 peticiones, el típico automatismo de alguien puesto sin control. En ( 4 ) , como os indique antes, si no proporcionamos un header X-NIFI-KEY correcto, nos redirige y si no continuamos a ( 3 ) , donde básicamente es un enrutador, basado en la URI que proporcionemos , en el ejemplo que he subido, tengo 3 distintos:
/crowdstrike/all nos dará las graficas anteriores, o para que podamos comprobar el potencial, metí /sin_conexion_30 o /sin_conexion_7 que nos dará los agentes sin conexión en 7 o 30 días.

Una pasemos esta pequeña «autenticación» , y siguiendo /crowdstrike/all de la salida inicial que he puesto, el siguiente paso, será obtener nuestro token Bearer sobre el que luego pidamos más información a la API de Crowdstrike:
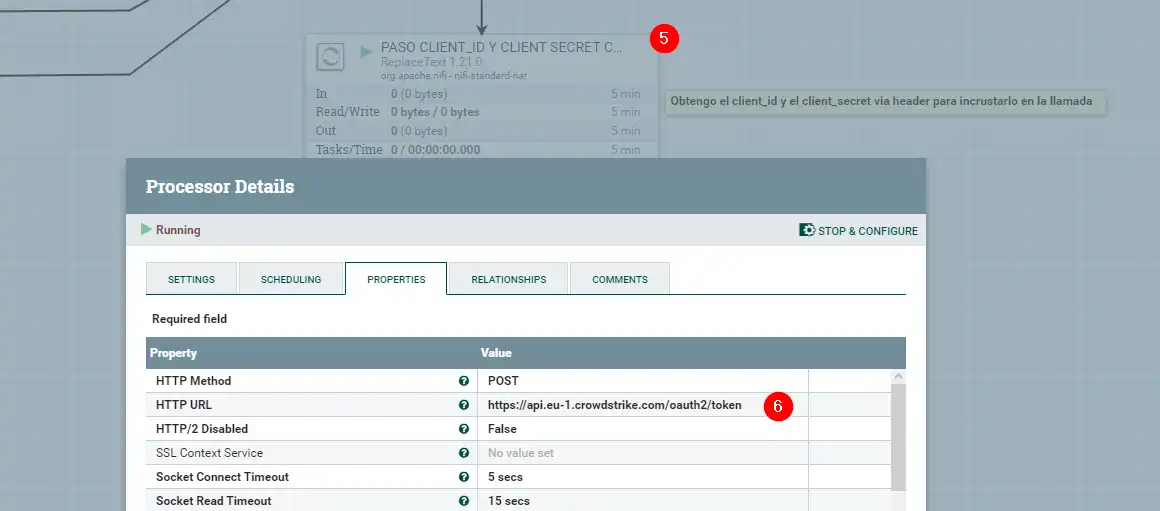
Con nuestro Token , ya tenemos la capacidad de pedir información a la API, por lo que solicitamos que nos devuelva todos los IDs ( 7 ). Si habeis trabajado con la API de Crowdstrike , conocereis las limitaciones, por lo que debemos tratarlo con el endpoint Scroll ( 8 ), que realiza un control sobre el Offset y con el que podremos realizar el bucle ( 9 ) a fin de que nos de todos los IDs. Con esto IDs, posteriormente se los pasaremos de 100 en 100 , donde nos devolverá toda la información de cada uno de los agentes, y sobre la que podremos pintar los datos que os muestro al inicio.
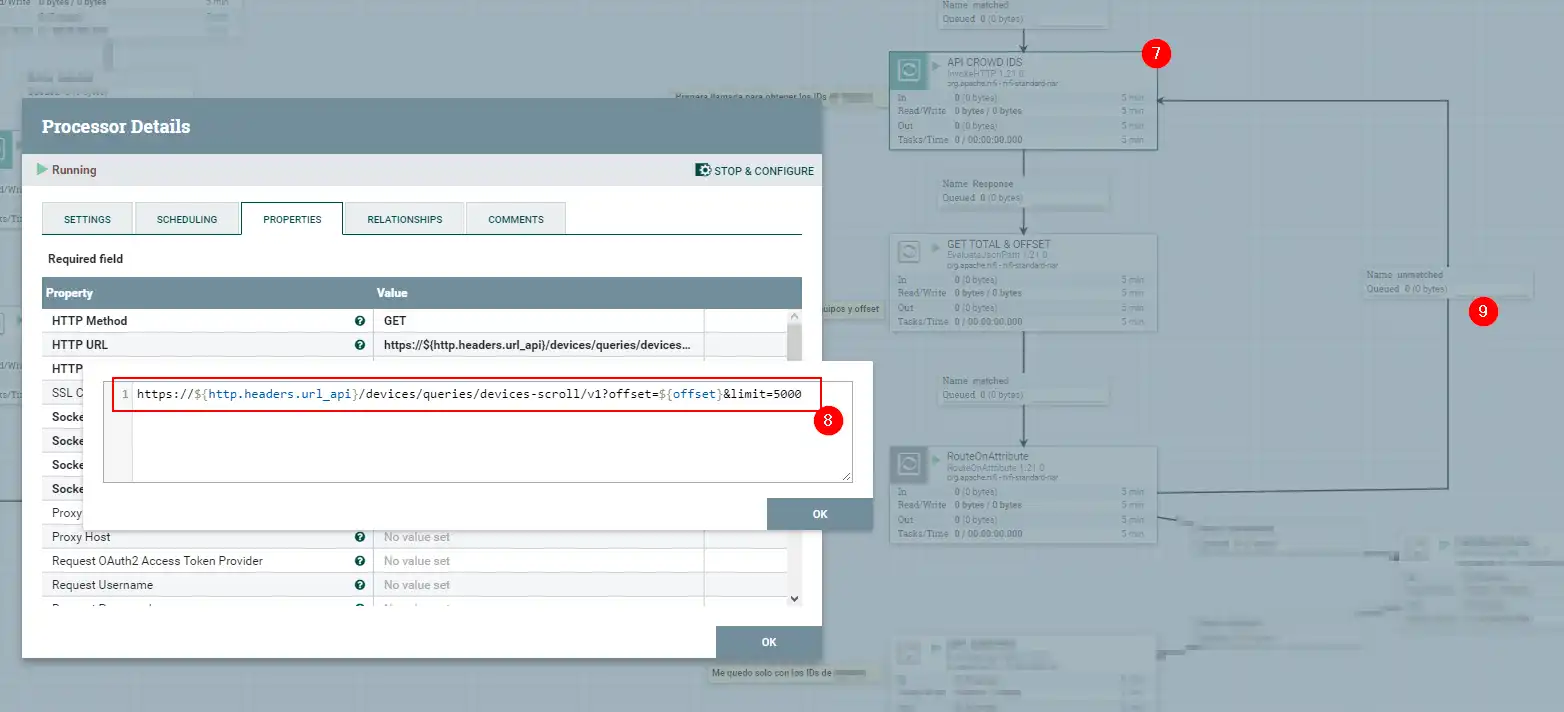
Me iré centrando solo en los componentes más relevantes, ya que he añadido varios ( que podrían eliminarse o comprimirse a fin de tratar la información ) , quitar caracteres, espacios … de una forma rudimentaria con NiFi, pero como veis , efectiva, y ojo, eficiente , ya que nos da mejores tiempos que el SDK.
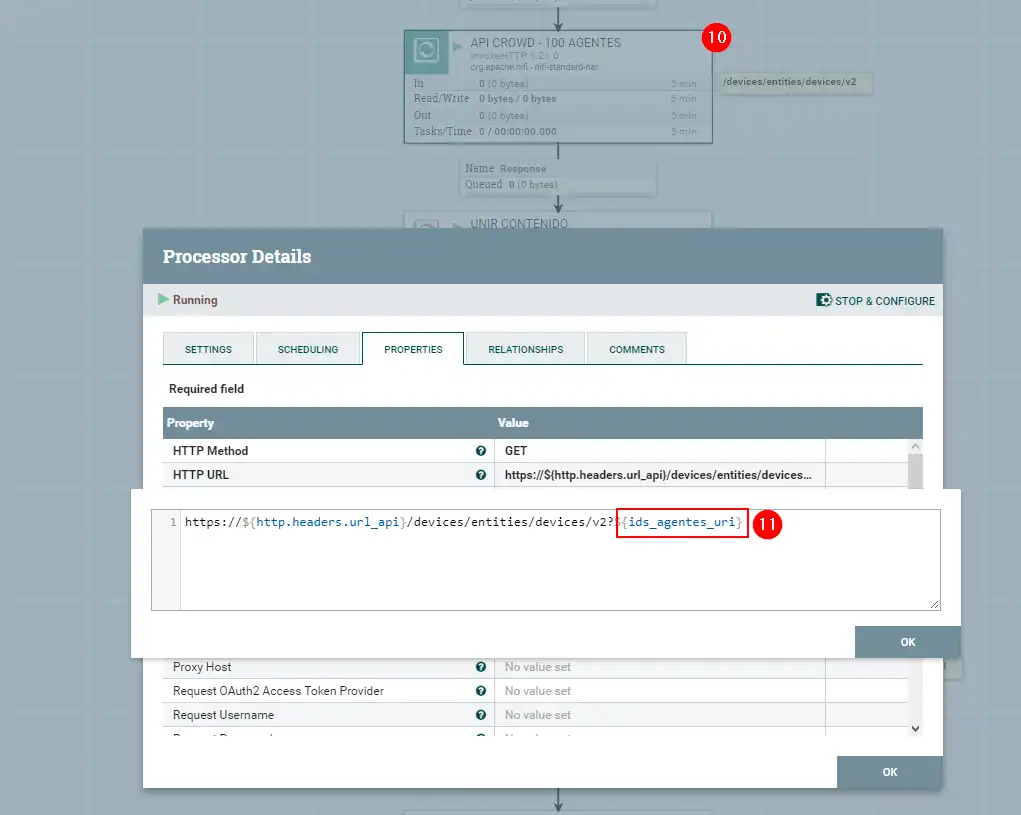
Una vez disponemos de todos los agentes agrupados en bloques de 100 ( el componente SPLIT superior al 10 ) , ya podemos solicitar toda la información de todos los agentes ( 10 ) , pasándole todos los bloques de IDs de nuestro parque, da igual lo grande que sea , como si nuestro parque tiene 200K agentes, haría 2000 peticiones y nos daría la información mascadita y tratada.
Como he comentado antes, dentro de las grandes capacidades de los componentes, se encuentra el tratamiento de información , desde texto a JSON, por lo que seria tan sencillo como leer todos datos con un JsonTreeReader y el componente CalculateRecordStats
Como os comentaba, esto solo es una mini PoC donde podéis haceros una idea de las grandes posibilidades que tendríamos. Desde obtener información , a montar nuestro propio XSOAR y bloquear dominios de forma automatizada en Firewalls , o recibir un Telegram con una incidencia Critica del sistema … solo poneros a imaginar … y seguro que podréis hacerlo con Apache NiFi.
Resultado del tratamiento de la API de Crowdstrike con Apache NiFi.
Si vamos a algo mas tangible, os pondré con la información que os mostraba, algunos gráficos interesantes y su motivación:
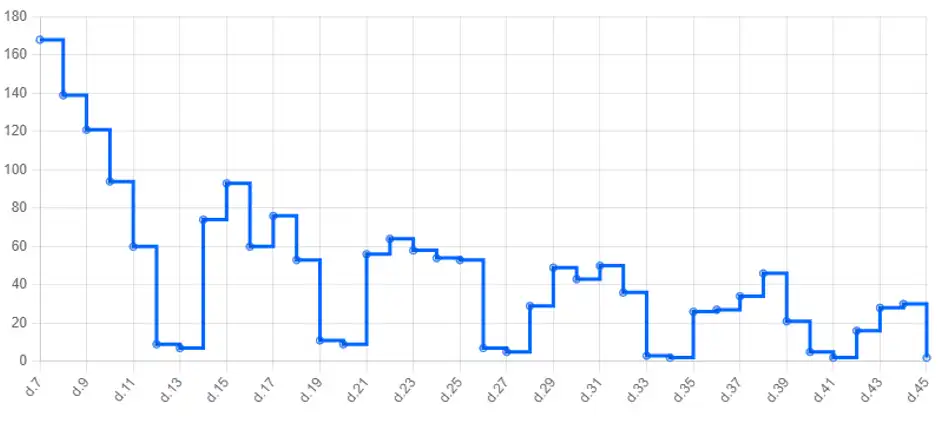
Podremos ver los agentes sin conexión de Crowdstrike por días por ejemplo. Tenemos la variante «vacaciones» de interferencia siempre, pero nos puede mostrar unido al despliegue de actualizaciones de agentes, posibles problemas. Por ejemplo, si empezamos a ver un incremento de equipos en desconexión , unido a actualizaciones de agentes o cambios, podremos detectar problemas como incompatibilidades, cortes de urls necesarias para el entorno en los Firewalls o similares.
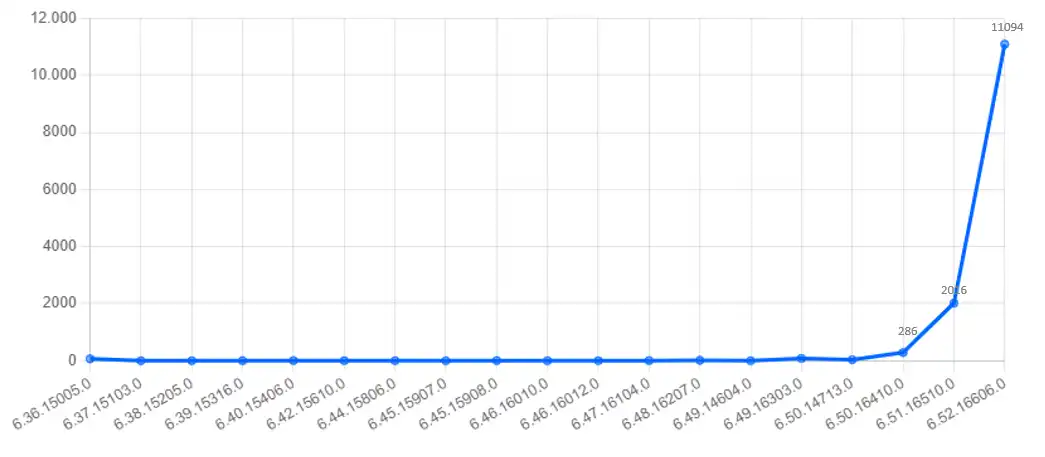
Podremos ver de una forma fácil e intuitiva, como de envejecido está nuestro parque de agentes Crowdstrike desplegados, hacer seguimiento del mismo en actualizaciones o similar.
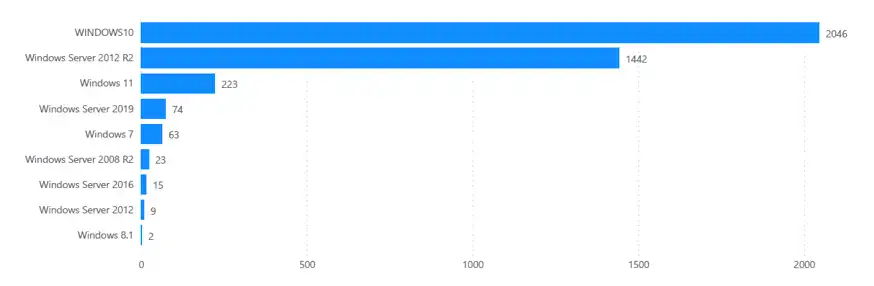
O ya no solo de agentes, si no también de nuestro parque de Sistema Operativo, sobre el cual podremos aplicar contramedidas en caso ataque , priorizando por los más vulnerables. La «teoría» de no tener sistemas como por ejemplo Windows 7 es muy bonita, pero no siempre podremos cambiar los sistemas o equipos, por lo que debemos convivir con ello, y trabajar de la mejor forma posible , asumiendo las dificultades del día a día de la operación.
Solo poneros a imaginar casos de uso con Apache NiFi. Como os comento, a mi me tiene enamorado desde el minuto 1 que empecé a jugar con el sistema. Si tenéis alguna duda, podéis escribirme en Linkedin sin problemas, ya que yo me tuve que pegar mucho con ello. Espero que os haya gustado el post y os sirva para obtener ideas fresquitas, que siempre se necesitan en ciberseguridad.
Powered by WPeMatico


