Cazando con Inteligencia Artificial: Detección de dominios maliciosos (II)
Esta entrada y la serie en su conjunto ha sido elaborada conjuntamente con Ana Isabel Prieto, Sergio Villanueva y Luis Búrdalo.
En el artículo anterior se comentó la dificultad ante la que los analistas de Threat Hunting se enfrentan como consecuencia de la alta cantidad de dominios que registra diariamente una organización. Esto dificulta el análisis y la localización de dominios potencialmente maliciosos, que pueden pasar desapercibido entre tanto tráfico. Por esta razón, en un intento de facilitar la tarea del analista, se propone la utilización de técnicas alternativas basadas en Machine Learning. Antes de presentar las diferentes pruebas realizadas, el artículo introduce los algoritmos que se van a utilizar para la detección de anomalías en los dominios.
Para empezar, es necesario comentar que tener una base de datos grande y variada es fundamental para que un modelo sea capaz de detectar dominios potencialmente maliciosos de forma fiable, ya que sus parámetros van a ser ajustados en un entorno que debe ser similar al real.
Sin embargo, existe una gran dificultad a la hora de identificar patrones en datos de alta dimensión, y más aún a la hora de representar dichos datos gráficamente y de expresarlos de forma que se destaquen sus similitudes y diferencias. Es aquí donde surge la necesidad de utilizar una herramienta potente de análisis de datos como el PCA (Principal Components Analysis).
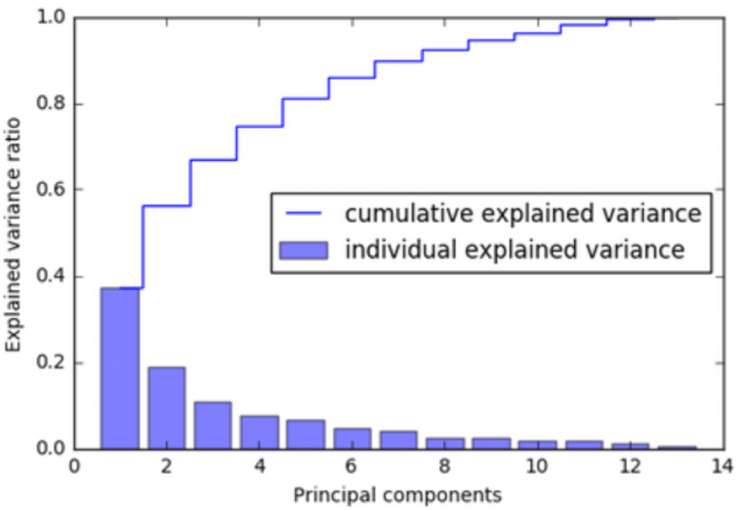
El principal objetivo del PCA es transformar un gran conjunto de variables en uno más pequeño que contenga la mayor parte de la información original. Para ello, se crean nuevas variables ficticias (componentes principales) en las direcciones de máxima varianza, a partir de la combinación lineal de las variables originales, por lo que cada componente principal contiene los pesos de cada una de las características originales. Además, estas nuevas variables no están correlacionadas entre sí, y se van calculando en función de la cantidad de variabilidad que explican, de forma que la primera componente principal es la que más variabilidad explica de los datos originales.
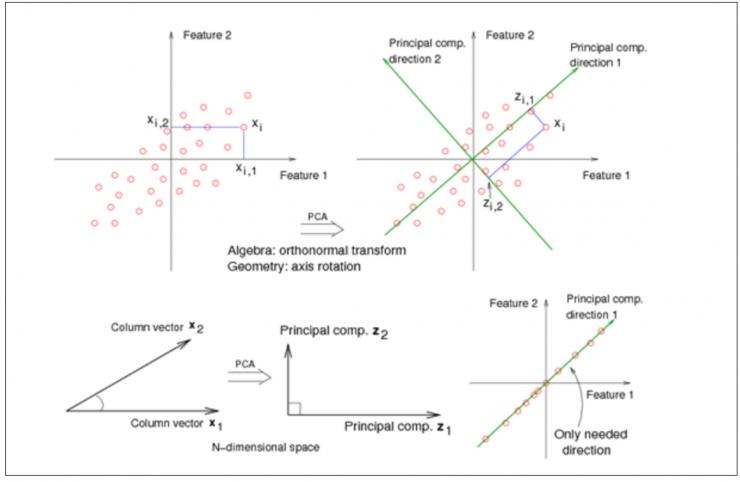
Además, dado que cada una de las componentes principales es una combinación lineal de las variables originales, ello permite conocer qué variables originales tienen más importancia en cada componente principal y, por tanto, identificar qué variable o variables han contribuido a que, por ejemplo, un determinado dominio se aleje del resto [2].
Para reducir la dimensionalidad del problema, a la base de datos original de dominios con sus características léxicas extraídas se le aplica un PCA, encargado de extraer tantas componentes principales (PC) como sean necesarias para explicar el 95% de la variabilidad de los datos. Después, serán estas nuevas variables sobre las que actuarán los modelos de clasificación no supervisada para etiquetar cada dominio como “normal” o “anómalo”.
Los algoritmos no supervisados escogidos en este caso para la detección de dominios anómalos han sido dos: Isolation Forest y One-Class SVM.
Isolation Forest
El primero de los algoritmos contemplados en este estudio es Isolation Forest [3]. Este algoritmo entraría dentro de la familia de los árboles de decisión, ya que combina la actuación de un conjunto de clasificadores “if-else”. Mediante cortes aleatorios en las variables del dataset, estos clasificadores aíslan las distintas observaciones del conjunto de datos, asignándole a cada una el promedio de cortes necesarios para su total aislamiento. Isolation Forest se basa en la premisa de que aquellas observaciones con características más peculiares quedarán aisladas más rápidamente del resto de datos, necesitando por ello menos particiones para su aislamiento [3].
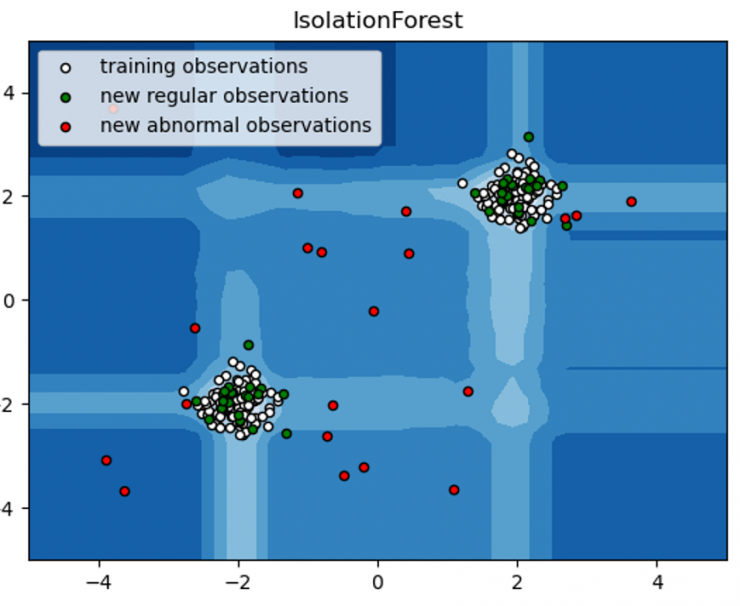
One Class SVM
El segundo algoritmo contemplado en este estudio es One Class SVM [5]. Se trata de una extensión de las clásicas máquinas de soporte vectorial para el caso de datos no etiquetados. Aquí, en lugar de separar dos clases mediante un hiperplano en el espacio de características, lo que se intenta es encuadrar la muestra de datos dentro de una hiperesfera de volumen mínimo, de forma que los puntos más alejados que quedan fuera se consideran outliers [5].

¿Qué se considera anómalo?
Es importante remarcar el hecho de que estos algoritmos clasifican como anómalos aquellos elementos que se diferencian significativamente del resto, lo cual no siempre se debe a que sean maliciosos. Por ejemplo, si se monitorizase la actividad de diferentes usuarios dentro de una organización, el comportamiento de los administradores de sistemas podría parecer anómalo simplemente porque llevan a cabo tareas específicas muy diferentes a las de los demás empleados.
Por otro lado, tampoco hay que asumir que la actividad maliciosa es significativamente menos frecuente que la actividad lícita. Por ejemplo, en caso de ataque por DoS, la actividad maliciosa sería mucho mayor que la lícita, de modo que los algoritmos empleados en esta serie de artículos podrían no servir para detectar dicha actividad.
En el siguiente post se presentarán las pruebas y resultados obtenidos al aplicar los algoritmos ya comentados, así como ciertos detalles sobre la base de datos con la que se ha trabajado.
Referencias
- [1] scikit-learn: Data Compression via Dimensionality Reduction I – Principal component analysis (PCA) – 2020. (2020). bogotobogo. https://www.bogotobogo.com/python/scikit-learn/scikit_machine_learning_Data_Compresssion_via_Dimensionality_Reduction_1_Principal_component_analysis%20_PCA.php
- [2] Shalizi, C. (2013). Advanced data analysis from an elementary point of view. Cambridge: Cambridge University Press.
- [3] Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008, December). Isolation forest. In 2008 eighth ieee international conference on data mining (pp. 413-422). IEEE. (https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf)
- [4] IsolationForest example. (2022). Retrieved 4 April 2022, from https://scikit-learn.org/stable/auto_examples/ensemble/plot_isolation_forest.html#sphx-glr-auto-examples-ensemble-plot-isolation-forest-py
- [5] Schölkopf, B., Williamson, R. C., Smola, A., Shawe-Taylor, J., & Platt, J. (1999). Support vector method for novelty detection. Advances in neural information processing systems, 12. (https://papers.nips.cc/paper/1999/file/8725fb777f25776ffa9076e44fcfd776-Paper.pdf)
- [6] One-Class SVM versus One-Class SVM using Stochastic Gradient Descent. (2022). Retrieved 4 April 2022, from https://scikit-learn.org/stable/auto_examples/linear_model/plot_sgdocsvm_vs_ocsvm.html#sphx-glr-auto-examples-linear-model-plot-sgdocsvm-vs-ocsvm-py
La entrada Cazando con Inteligencia Artificial: Detección de dominios maliciosos (II) aparece primero en Security Art Work.
Powered by WPeMatico