
Tipos de redes P2P (Peer To Peer) y diferencias entre ellas

La sociedad de hoy en día necesita un abundante intercambio de información para el desarrollo de la mayoría de las actividades o trabajos. Por ejemplo, las empresas, sobre todo multinacionales, distribuyen sus proyectos entre las numerosas sedes que tienen por todo el mundo; esto supone que entre las distintas sedes deba de haber una comunicación y un intercambio de información para el buen desarrollo de sus proyectos. Otro ejemplo son las universidades, que necesitan un sistema para intercambiar información con los estudiantes, para proporcionarles apuntes, exámenes etc.
Es por esto que hacia 1996, surge la primera aplicación P2P de las manos de Adam Hinkley, Hotline Connect, que pretendía ser una herramienta destinada a universidades y empresas para la distribución de archivos. Esta aplicación utilizaba una estructura descentralizada y no tardó mucho en quedar obsoleto (por depender de un único servidor); y como fue diseñado para Mac OS, no produjo un gran interés por los usuarios.
Es con Napster, en 1999, cuando el uso de las redes P2P suscitó curiosidad entre los usuarios. Este sistema de intercambio de música, utilizaba un modelo híbrido de red P2P, puesto que aparte de la comunicación entre pares, incluyó un servidor central para organizar dichos pares. Su principal problema era que el servidor introducía puntos de ruptura y una gran posibilidad de que se produjeran cuellos de botella.
Es por esto que van surgiendo nuevas topologías como la descentralizada, cuya principal característica es que no necesita un servidor central para organizar la red; un ejemplo de esta topología es Gnutella. Otro tipo son las redes P2P estructuradas, que se centran en la organización del contenido en lugar de organizar a los usuarios; como ejemplo destacamos JXTA. También tenemos las redes con Tabla de Hashes Distribuida (DHT), como por ejemplo Chord.
A continuación, desarrollaremos los tipos de redes P2P mencionadas anteriormente.
Primeros sistemas P2P: un enfoque híbrido
Los primeros sistemas P2P, como Napster o SETI@home, fueron los primeros en trasladar las tareas más pesadas desde los servidores a los ordenadores de los usuarios. Con la ayuda de Internet, que permite combinar todos los recursos que los usuarios aportan, consiguieron que estos sistemas alcanzaran una mayor capacidad de almacenamiento y un mayor poder de computación que los servidores. Pero el problema residía en que sin una infraestructura que actuara de intermediaria entre las entidades pares, el sistema se convertiría en un caos, ya que cada par acabaría actuando de forma independiente.
La solución para el problema del desorden, es introducir un servidor central, que se encargará de coordinar a los pares (la coordinación entre pares puede variar mucho de unos sistemas a otros). A este tipo de sistemas se les denomina sistemas híbridos, puesto que combinan el modelo cliente-servidor, con el modelo de las redes P2P. Mucha gente opina que este enfoque no debe calificarse como un sistema P2P real, pues introduce un componente centralizado (servidor), pero a pesar de esto, este enfoque ha tenido y sigue teniendo mucho éxito.
En este tipo de sistemas, cuando una entidad se conecta a la red (utilizando una aplicación P2P), ésta se registra en el servidor, de manera que el servidor tiene controlado en todo momento el número de pares que hay registrados en ese servidor, permitiéndoles ofrecer servicios al resto de pares. Normalmente la comunicación entre pares se realiza punto a punto, ya que los pares no forman ninguna red importante.
El principal problema que presenta este diseño es que introduce un punto de ruptura del sistema y una alta probabilidad de que se produzca lo denominado “cuello de botella” (En la transferencia de datos, cuando la capacidad de procesamiento de un dispositivo es mayor que la capacidad al que se encuentra conectado el dispositivo). Si la red crece, la carga del servidor también crecerá y si el sistema no es capaz de escalar la red, ésta se colapsaría. Y si el servidor falla, la red no sería capaz de reorganizarse.
Pero a pesar de todo, todavía hay muchos sistemas que utilizan este modelo. Este enfoque es útil para sistemas que no pueden tolerar inconsistencias y no necesitan gran cantidad de recursos para las tareas de coordinación. A modo de ejemplo, presentamos a continuación el modo de actuar de Napster. Napster surge a finales de 1999, de la mano de Shawn Fanning y Sean Parke, con la idea de compartir archivos de música entre los usuarios.

El funcionamiento de Napster consiste en que los usuarios deben conectarse a un servidor central, que se encarga de mantener una lista de los usuarios conectados y de los archivos disponibles en dichos usuarios. Cuando un usuario quiere obtener un archivo, realiza una búsqueda en el servidor y éste le proporciona una lista con todos los pares que tienen el archivo que busca. Así, el interesado busca al usuario que mejor le puede proporcionar lo que necesita (seleccionando los que mejor tasa de transferencia tengan, por ejemplo) y obtiene directamente de él su archivo, sin intermediarios. Napster pronto se convirtió en un sistema muy popular entre los usuarios, alcanzando los 26 millones de usuarios en el 2001, lo que produjo el malestar de las discográficas y músicos.
Es por ello que la RIAA (Recording Industry Association of America) y varias discográficas, en el intento de acabar con ella, interpusieron una demanda a la empresa, lo que originó el cierre de sus servidores. Esto produjo un colapso en la red, puesto que los usuarios no eran capaces de descargar sus archivos de música. Como consecuencia, en lugar de terminar con la “piratería”, una gran parte de usuarios emigraron a otros sistemas de intercambio como Gnutella, Kazaa, etc.
Más tarde, hacia 2008, Napster se convirtió en una empresa de venta de música MP3, con una gran cantidad de canciones para descargar: free.napster.com.
Redes P2P no estructuradas
Otro modo de compartir archivos es utilizando una red no centralizada, es decir, una red donde se elimina cualquier tipo de intermediario entre los usuarios de forma que es la propia red la encargada de organizar la comunicación entre pares.
En este enfoque, si se conoce a un usuario, se establece una “unión” entre ellos, de manera que forman una “red”, que se puede unir a más usuarios. Para encontrar un archivo, un usuario emite una consulta, que va inundando toda la red, con el objetivo de encontrar el máximo de usuarios que posean esa información.
Por ejemplo, para realizar una búsqueda en Gnutella, el usuario interesado emite una petición de búsqueda a sus vecinos, y estos a los suyos. Pero para evitar colapsar la red con una pequeña consulta, el horizonte de difusión está limitado a una determinada distancia desde el host original y también el tiempo de vida de la petición, pues cada vez que el mensaje es reenviado hacia otro usuario, su tiempo de vida disminuye.
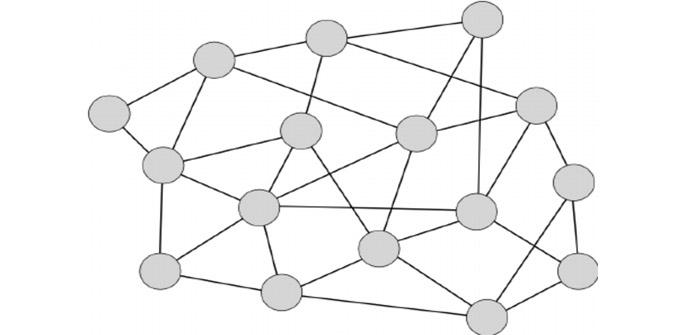
El principal problema de este modelo es que si la red crece, el mensaje de consulta solo llegará a unos pocos usuarios. Si lo que buscamos es algo muy conocido, seguramente cualquier host dentro de nuestro horizonte de difusión lo tendrá, pero en cambio, si lo que buscamos es algo muy especial, posiblemente no lo encontremos porque al tener limitado el horizonte de difusión, habremos dejado fuera a hosts que a lo mejor contenían la información que andamos buscando.
A día de hoy, las redes P2P no centralizadas puras has sido sustituidas por nuevas tecnologías, como es el caso de los Supernodos.
SUPERNODOS, una jerarquía en las redes no estructuradas
Los principales problemas de las redes no estructuradas eran el horizonte de difusión y el tamaño de la red. Tenemos dos posibles soluciones: o aumentamos el horizonte de difusión, o disminuimos el tamaño de la red. Si elegimos aumentar el horizonte de difusión, aumentamos el número de hosts a los que debemos enviar el mensaje de consulta exponencialmente. Esto provocaría, como ya hemos visto, problemas en la red, como el colapso de la misma. Por el contrario, si elegimos disminuir el tamaño de la red, los sistemas son capaces de escalar mucho mejor por la red, usando los supernodos.
La idea principal de este sistema es que la red se divide entre numerosos nodos terminales y un pequeño grupo de supernodos bien conectados entre ellos, a los que se conectan los nodos terminales. Para poder ser un supernodo, es necesario ser capaz de ofrecer suficientes recursos al resto de usuarios, especialmente ancho de banda. Esta red de supernodos, a la que solo unos pocos pueden pasar a formar parte, es la encargada de mantener el tamaño de la red lo suficientemente pequeña para no perder eficiencia en las búsquedas.
Su funcionamiento es similar al del modelo híbrido, puesto que los nodos terminales se conectan a los supernodos, que toman el papel de servidores, de manera que los usuarios sólo se conectan con otros usuarios para realizar exclusivamente las descargas. Los supernodos almacenan información sobre lo que cada usuario posee, de manera que puede reducir el tiempo de una búsqueda, enviando la información hacia los nodos terminales que poseen lo que estamos buscando.
Este tipo de estructura todavía se sigue usando mucho hoy en día, sobre todo porque es muy útil para intercambiar información de contenido popular o para realizar búsquedas por palabras claves. Como la red de supernodos está reducida, estos sistemas escalan muy bien por la red y no ofrecen puntos de ruptura como el modelo híbrido. En cambio, disminuyen la robustez frente a ataques y caídas de la red y pierden precisión en la búsqueda de resultados, por la réplica a través de los supernodos. Si un pequeño número de supernodos falla, la red se divide en pequeñas particiones.
Redes P2P estructuradas
Este enfoque se desarrolla en paralelo con el enfoque de supernodos descrito anteriormente. Su principal característica es que en lugar de encargarse de organizar los nodos, se centra en la organización del contenido, agrupando el contenido similar en la red y creando una infraestructura que permite una búsqueda eficiente, entre otras cosas.
Los pares organizan entre ellos una nueva capa virtual de red, “una red superpuesta”, que se sitúa por encima de la red P2P básica. En esta red superpuesta, la proximidad entre host viene dada en función del contenido que compartan: estarán más cerca unos de otros cuantos más recursos en común proporcionen. Así garantizamos que la búsqueda se realice con eficiencia dentro de un horizonte no muy lejano y sin reducir el tamaño de la red. Como ejemplo, JXTA, donde los pares actúan en una red virtual y son libres de formar y dejar grupos de pares. Así, los mensajes de búsqueda, normalmente se quedan dentro de la red virtual y el grupo actúa como un mecanismo de agrupación, combinando pares con los mismos intereses o similares.
Este enfoque ofrece un gran rendimiento y unas búsquedas exactas, si la red virtual refleja con precisión la similitud entre los nodos respecto a las búsquedas. Pero también tiene una serie de inconvenientes: posee un alto coste de establecimiento y mantenimiento de la red virtual en sistemas donde los hosts entran y salen muy rápido; no son muy apropiados para búsquedas que incluyen operadores booleanos, ya que se necesitarían nodos que fueran capaces de realizar búsquedas con más de un término.
Una subclase dentro de este tipo de redes P2P, son las tablas de hashes distribuído.
Tablas Hash distribuido (DHT)
La característica principal de las DHT es que no organizan la red superpuesta por su contenido ni por sus servicios. Estos sistemas dividen todo su espacio de trabajo mediante unos identificadores, que le son asignados a los pares que utilizan esta red, haciéndoles responsable de una pequeña parte del espacio total de trabajo. Estos identificadores pueden ser, por ejemplo, los números enteros comprendidos en el rango [0, 2n-1], siendo n un número fijo.
Cada par que participa en esta red, actúa como una pequeña base de datos (el conjunto de todos los pares formaría una base de datos distribuida). Dicha base de datos, organiza su información en parejas (clave, valor). Pero para saber qué par es el encargado de guardar esa pareja (clave, valor), necesitamos que la clave sea un entero dentro del mismo rango con el que se numera a los pares participantes de la red. Puesto que la clave puede no estar representada en los números enteros, necesitamos una función que convierta las claves en enteros dentro del mismo rango con el que se numera a los pares. Dicha función es la función hash. Esta función tiene la característica de que ante distintas entradas, puede dar el mismo valor de salida, pero con una probabilidad muy baja. Por eso en lugar de hablar de una “base de datos distribuida”, se habla de Tabla de Hashes Distribuida (DHT), porque lo que en realidad guarda cada par de la pareja (clave, valor), no es la clave como tal, sino el hash de la clave.
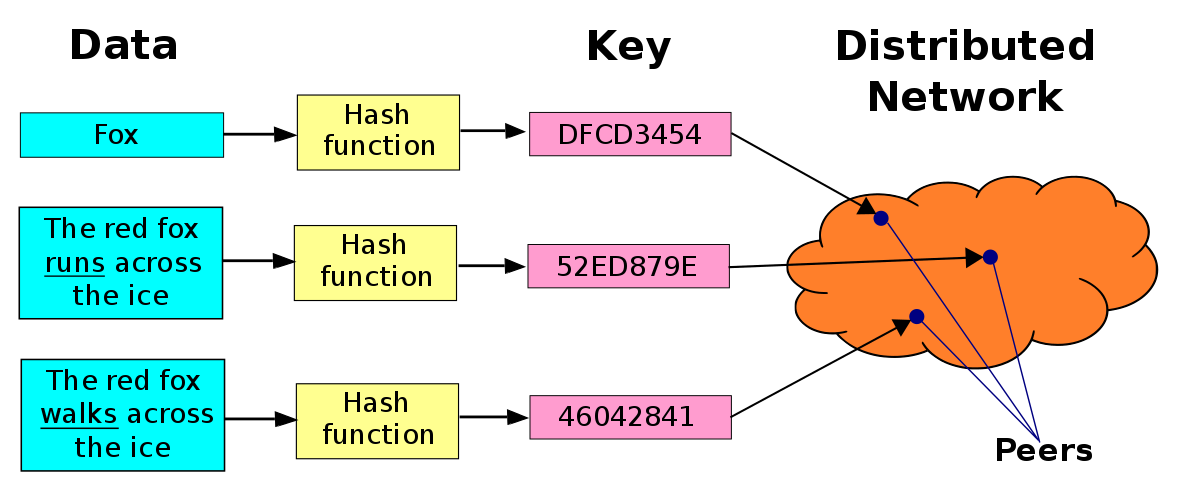
Ya hemos comentado que cada par es responsable de una porción del espacio de trabajo de la red. Pero, ¿cómo se asigna la pareja (clave, valor) al par adecuado? Para ello se sigue una regla: una vez calculado el hash de la clave, la pareja (clave, valor) se le asigna al par cuyo identificador sea el más cercano (el inmediato sucesor) al hash calculado. En el caso de que el hash calculado sea mayor que los identificadores de los pares, se utiliza el convenio módulo 2n.
Una vez que hemos hablado un poco del funcionamiento básico de las DHT, vamos a ver un ejemplo de su implementación, a través del protocolo CHORD.
Protocolo de búsqueda distribuida en redes P2P: CHORD
Chord es uno de los protocolos más populares de búsqueda distribuida en redes P2P. Esté protocolo utiliza la función hash SHA-1 para asignar, tanto a los pares como a la información almacenada, su identificador. Estos identificadores están dispuestos en círculo (tomando todos los valores módulo 2m), de forma que cada nodo conoce quién es su antecesor y su sucesor más inmediato.
Para poder mantener la escalabilidad de la red, cuando un nodo abandona la red, todas sus claves pasan a su inmediato sucesor, de forma que siempre se mantiene al día la red, evitando así que las búsquedas pudieran ser erróneas.
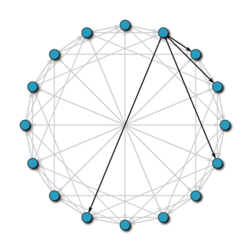
Para encontrar al responsable que almacena una clave, los nodos se van enviando mensajes entre sí hasta que lo encuentran. Pero, debido a la disposición en círculo de la red, en el peor de los casos, una consulta puede llegar a recorrer la mitad de los nodos, provocando que sea muy caro mantenerlo. Para evitar esto, y así reducir coste, cada nodo tiene guardada una tabla de enrutamiento, en la cual se almacena la dirección de nodos que distan una cierta distancia del mismo. De esta forma, cuando queramos saber el encargado de la clave k, el nodo busca en su tabla de enrutamiento si tiene la dirección del responsable de k; si la tiene, le envía la petición directamente; si no lo tiene, le envía la pregunta al nodo más cercano de k, cuyo identificador sea menor que k.
Con esta mejora hemos conseguido rebajar el coste de las búsquedas de N/2 a log N, siendo N el número de nodo de la red.
Conclusiones
Como hemos visto, hay muchos tipos de redes P2P, cada una con sus virtudes y sus defectos. Ninguna destaca por encima de otra, lo que permite que, a la hora de programar, por ejemplo, una aplicación P2P, tener varias opciones, cada una de ellas con sus propias características.
Una cosa a tener en cuenta es como está evolucionando la forma de compartir la información. A finales del milenio pasado, el uso de redes P2P era abundante y, para la mayoría de la gente era la única forma conocida para compartir la información. Hoy en día la tendencia ha cambiado. La gente ahora prefiere intercambiar los archivos a través de grandes servidores donde en algunos casos, pagan a los usuarios por hospedarse en ellos.
Algunas preguntas que se nos pueden venir a la cabeza son: ¿Cuál es el futuro de las redes P2P? ¿Hacia qué formas de organizar la información evolucionamos?
Una de las posibles evoluciones es el salto del P2P al p4p. ¿Qué es el P4P? A modo de resumen diremos que el P4P, también conocido como P2P híbrido, es una pequeña evolución del P2P cuya principal característica es que los proveedores de servicio, los ISP, forman un papel esencial dentro de la red, ya que a la hora de hacer una búsqueda, primero se buscará entre los nodos participantes que pertenezcan al mismo ISP.
El artículo Tipos de redes P2P (Peer To Peer) y diferencias entre ellas se publicó en RedesZone.
Powered by WPeMatico


