Ransomware ate my network (V)
Entradas de la serie:
=> Primera parte
=> Segunda parte
=> Tercera parte
=> Cuarta parte
=> Quinta parte
En el artículo anterior ya habíamos terminado el análisis forense del incidente, por lo que Ángela ya tenía una visión global de todo lo que había ocurrido. Los timelines son una herramienta de análisis sensacional para poder entender lo ocurrido en un incidente, así que construimos una (con las horas en UTC, no perdamos las buenas costumbres):
- 4/Nov: Los atacantes envían los correos con enlaces maliciosos a personal de la FFP.
- 9/Nov – 11:37h – dolores.jolgorio abre el correo, descarga y ejecuta el .doc con la macro maliciosa.
- 11:38h – El equipo se infecta con un agente de Meterpreter.
- 11:41h – Los atacantes ejecutan diversos comandos para reconocer el sistema.
- 11:46h – Los atacantes “revenden” el acceso al segundo grupo, cediendo el control con un agente de Empire.
- 12:01 – Los atacantes elevan privilegios con un exploit de la vulnerabilidad CVE-2020-0787.
- Entre las 12:01 y las 12:37h: Vuelcan hashes con la funcionalidad Powerdump de Empire.
- 12:37h – Lanzan SharpHound e identifican W10-PC3 como equipo con una sesión iniciada de administrador de dominio.
- 13:16h – Con los permisos de administrador local, copian el stager de Empire a W10-PC3 y lo ejecutan con PsExec.
- Entre las 13:16 y las 13:30h – Obtienen el hash NTLM de la cuenta dom.adm con Mimikatz.
- 13:51h – Montan el pivot SSH-RDP y acceden al DC con el hash NTLM de la cuenta dom.adm.
- 13:55h – Copian el fichero temp.zip con las GPO y scripts de Powershell.
- 13:57h – Despliegan la GPO “All in One”, que erosiona severamente la seguridad de los equipos del dominio.
- 15:08h – Despliegan la GPO “Scheduler”, que copia el ransomware a los equipos y deja programada una tarea para su ejecución a las 17:15h.
- 15:13h – Lanzamiento de un agente de Empire.
- 15:30h – Saltan las alertas en GLORIA.
Una vez tiene la certeza de que ha comprendido las acciones de los atacantes en su totalidad, Ángela puede pasar a erradicar de forma definitiva a los atacantes y recuperar los sistemas a la normalidad. Para ello toma las siguientes medidas:
- Eliminar las GPO maliciosas de los equipos (ya hecho).
- Bloquear el rango IP 101.132.122.0/24 en el cortafuegos (mejor que sobre que no que falte), y crear una regla en el Suricata que alerte de cualquier contacto con esas IP (por si nos hemos dejado algo pendiente).
- Restaurar el DC a un snapshot de la madrugada del 8 al 9 de noviembre, realizando un volcado de la memoria y comprobando que no hay agentes de Empire o Meterpreter desplegados.
- Plataformar con extremo prejuicio los equipos W10-PC3 y W10-PC5.
- Lanzar un script que compruebe que el equipo/servidor no tiene los ejecutables de Ryuk (y por ende, no está infectado), creando una lista de equipos limpios. Aquellos equipos que no puedan ser verificados (porque no estaban encendidos o porque los usuarios se los llevaron a casa), se mueven a una VLAN de “cuarentena” sin acceso a recursos de red hasta que se comprueba de forma manual que no están afectados.
- Forzar un cambio de contraseña de TODAS las cuentas del dominio (los atacantes han tenido acceso al DC, y aunque volver a un snapshot elimine un Golden Ticket, se han podido llevar los hashes de todas las cuentas del dominio), con especial cuidado en las cuentas de servicio (las grandes olvidadas).
- Levantar de nuevo los servidores de ficheros, y habilitar de nuevo las carpetas compartidas.
- Crear una GPO que revierta los cambios llevados a cabo por la GPO “apisonadora” de la seguridad.
Una vez Ángela tiene la situación controlada es el momento de diseminar los resultados de la respuesta ante incidentes. Para ello crea un ticket en LUCIA (la herramienta de gestión de incidentes del CCN-CERT), haciendo un resumen de lo ocurrido y aportando todos los IOC que se han encontrado. De esta forma el CCN-CERT puede analizar el incidente, enriquecer los IOC con sus fuentes propias y distribuirlo al resto de la AAPP vía REYES.
Cuando el incidente esté definitivamente cerrado, Ángela terminará de escribir un informe de incidente completo, que presentará de forma interna ante la dirección del MINAF, enviará al CCN-CERT y guardará en el archivo de incidentes de seguridad.
Una semana más tarde, el CCN-CERT informa a Ángela que el ataque ha sido realizado (con fiabilidad media/alta) por un grupo de HOR (Human-Operated Ransomware) basado en Bielorrusia.
La atribución es siempre un tema sensible, por lo que de forma interna habían recogido las siguientes evidencias:
- Los nombres de los ejecutables estaban en ruso (pero cualquiera puede poner a sus ficheros el nombre que quiera)
- Las IP desde las que se ha realizado el ataque están en China (pero los atacantes pueden conseguir un hosting y/o comprometer un servidor en el país que deseen).
- Las credenciales de uno de los servidores de los atacantes eran “dimitri/dosdivanya2020”. Este indicio ya es un poco más fiable (se puede falsificar pero es más de “bajo nivel”).
- Discrepancia horaria entre el despliegue de la GPO del ransomware y la programación de la tarea programada. Aquí sí que tenemos juego. Los atacantes despliegan la GPO a las 15:08h UTC … pero la programan para que se lance a las 17:15h. Si Ángela fuera mala, habría programado la tarea para lanzarse a las 15:15h, y de esa forma minimizar el tiempo de respuesta de los defensores. Si examinamos el script en Powershell que importaba la GPO, vemos algo curioso:
$mon = get-date -format MM
$day = get-date -format dd
$h = Read-Host "Enter hours"
$m = Read-Host "Enter minutes"
$s = Read-Host "Enter seconds"
$sdate = $date+"T"+$h+':'+$m+':'+$s
# Change dates to maximum effect
$4f = Get-Content "C:tempScheduler{879F6C5A-B213-42A1-9900-6A9900C39EC3}DomainSysvolGPOMachinePreferencesScheduledTasksScheduledTasks1.xml"
$newschedc = foreach ($s1 in $4f){$s1. replace("2019-11-12T23:11:11","$sdate")}
$newschedc | Set-Content "C:tempScheduler{879F6C5A-B213-42A1-9900-6A9900C39EC3}DomainSysvolGPOMachinePreferencesScheduledTasksScheduledTasks.xml"
El segundo bloque de código reemplaza la fecha de inicio del ransomware en el fichero base que configura la tarea programada. Y la fecha de inicio la saca del valor que se introduce al ejecutarse el script; es decir, cuando los atacantes desplegaron esta GPO, en ese mismo momento le dijeron a qué hora tenía que ejecutarse.
Es posible que los atacantes miraran su reloj y quisieran decir “lánzate dentro de 7 minutos” … pero en realidad la lanzaran pasadas dos horas y 7 minutos. Ese error podría indicar que los atacantes estaban en una zona horaria con 2h de diferencia con España (que recordemos está en UTC+1).
Ángela revisa qué países tienen como zona horaria UTC+3 y con una población importante de ruso hablantes, y obtienen 3 candidatos: Rusia (lógico), Ucrania y Bielorrusia. Ucrania tiene la mayor parte del país en UTC+2, estando solo una fracción en UTC+3. Rusia abarca de UTC+2 a UTC+12, pero es interesante ver que Moscú está en UTC+3. Bielorrusia opera por completo en UTC+3. Hasta ahí puede llegar, y si el CCN-CERT afirma que es Bielorrusia será porque tiene fuentes que así lo aseguran…
¿Qué ha aprendido el MINAF del incidente? La fase de las lecciones aprendidas suele ser el patito feo de la gestión de incidentes, pero es vital para repasar lo que se ha hecho bien y lo que se ha hecho mal, para de esta forma poder corregir nuestros errores y mejorar nuestras capacidades de cara al siguiente incidente. Tenemos las siguientes lecciones aprendidas:
- Las fusiones con prisas no son buenas: El MINAF tuvo que absorber a la FFP a marchas forzadas, y sin un plan de integración y armonización de las buenas prácticas de seguridad. A causa de estas prisas, la carencia de medidas de seguridad apropiadas de la FFP ha provocado el incidente de seguridad.
- Los sistemas tienen que estar actualizados: La FFP tenía retrasos de más de 6 meses en sus actualizaciones de seguridad, y posiblemente sucedería lo mismo con su protección antivirus. No desplegar las actualizaciones en un plazo razonable (entre una semana y un mes) supone correr el riesgo de ser atacados con éxito. Hay que integrar correctamente los equipos de la FFP dentro de los procedimientos de actualización ya existentes en el MINAF.
- Misma contraseña de administrador local para todos los equipos: Aunque facilita en gran medida las tareas de administración, también facilita las tareas de los atacantes ya que posibilita el movimiento lateral de los mismos. Se debe extender el LAPS ya existente en los equipos del MINAF a los equipos de la FFP.
- Inicio de sesión de administradores de dominio en los puestos de usuario: En muchos casos uno de los objetivos principales de los atacantes es hacerse con las credenciales de un administrador de dominio, ya que con ellas tienen vía libre por todo el dominio. Se debe extender la prohibición ya existente en los equipos del MINAF que prohíbe a los administradores de dominio iniciar sesión en los equipos.
- Una detección y respuesta rápidas son vitales: El MINAF se ha salvado en gran medida gracias a la rapidísima detección del incidente, unido a la pronta respuesta. El uso de capacidades avanzadas de detección y alerta va a ser cada vez más importante para reaccionar lo antes posible a este tipo de incidentes.
- La detección en el puesto de usuario es fundamental: En este caso el MINAF tenía desplegado CLAUDIA, una herramienta de detección en el equipo que ha permitido obtener con detalla prácticamente todas las acciones de los atacantes. Disponer de herramientas EDR (Endpoint Detection & Response) es cada día más importante. https://www.ccn-cert.cni.es/soluciones-seguridad/claudia.html
- La fuerza del enemigo puede ser usada en su contra: los atacantes han hecho uso de herramientas ofensivas de código abierto, que se han podido analizar y han ayudado a analizar las acciones realizadas por los atacantes.
- La concienciación sigue siendo necesaria: Los usuarios siguen siendo parte fundamental de cualquier estrategia de ciberseguridad. Se deben realizar tanto campañas de concienciación como acciones que permitan mantener a los usuarios alerta y preparados ante este tipo de ataques.
Analizando el incidente en retrospectiva, Ángela piensa “menos mal que en el fondo tuvimos suerte y nos tocaron los patanes”. Por muy triste que parezca, este tweet de @malcomvetter resume bastante bien la situación actual del ransomware:
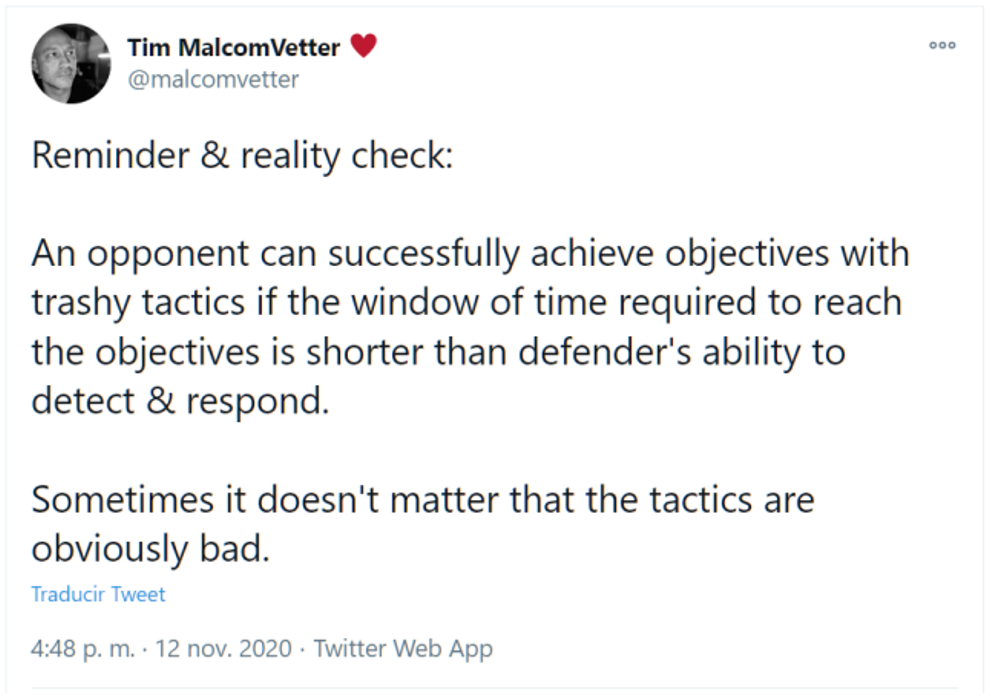
Da igual que los atacantes sean unos cutres (que lo han sido): si con sus técnicas chapuceras son capaces de conseguir sus objetivos en menos tiempo del que el MINAF puede detectar y responder… perdemos.
Mientras da un sorbo a su single malt (recompensa personal por haber resuelto otro incidente de los gordos) y fantasea con dar aplicación profusa y alegre de su látigo Ethernet (CAT6e) a los responsables de la fusión con la FFP, Ángela piensa … “otro día más dando servicio, que no es poco”. Que, al final, es lo que importa.
Referencias:
Human-operated ransomware attacks: A preventable disaster
Ransomware groups continue to target healthcare, critical services; here’s how to reduce risk
Defending networks against human-operated ransomware
Ryuk’s Return
Ryuk in 5 hours
Ryuk Speed Run, 2 hours to Ransom
Ryuk and GPOs and Powershell, Oh My!
https://thebinaryhick.blog/2019/12/22/ryuk-and-gpos-and-powershell-oh-my/
La entrada Ransomware ate my network (V) aparece primero en Security Art Work.
Powered by WPeMatico